2023-04-26 17:34:12 +03:00
|
|
|
|
Realtime Voice Changer Client for RVC チュートリアル(v.1.5.2.5)
|
2023-04-24 03:06:28 +03:00
|
|
|
|
================================================================
|
|
|
|
|
|
# はじめに
|
|
|
|
|
|
本アプリケーションは、各種音声変換 AI(VC, Voice Conversion)を用いてリアルタイム音声変換を行うためのクライアントソフトウェアです。本ドキュメントでは[RVC(Retrieval-based-Voice-Conversion)](https://github.com/liujing04/Retrieval-based-Voice-Conversion-WebUI)に限定した音声変換のためのチュートリアルを行います。
|
|
|
|
|
|
|
2023-04-28 14:07:58 +03:00
|
|
|
|
以下、本家の[Retrieval-based-Voice-Conversion-WebUI](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI)を本家RVCと表記し、ddPn08氏の作成した[RVC-WebUI](https://github.com/ddPn08/rvc-webui)をddPn08RVCと記載します。
|
2023-04-26 17:34:12 +03:00
|
|
|
|
|
|
|
|
|
|
|
2023-04-24 03:06:28 +03:00
|
|
|
|
## 注意事項
|
|
|
|
|
|
|
|
|
|
|
|
- 学習については別途行う必要があります。
|
2023-04-28 14:07:58 +03:00
|
|
|
|
- 自身で学習を行う場合は[本家RVC](https://github.com/liujing04/Retrieval-based-Voice-Conversion-WebUI)または[ddPn08RVC](https://github.com/ddPn08/rvc-webui)で行ってください。
|
2023-04-25 16:03:16 +03:00
|
|
|
|
- ブラウザ上で学習用の音声を用意するには[録音アプリ on Github Pages](https://w-okada.github.io/voice-changer/)が便利です。
|
|
|
|
|
|
- [解説動画](https://youtu.be/s_GirFEGvaA)
|
2023-04-24 03:06:28 +03:00
|
|
|
|
- [trainingのTIPS](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/training_tips_ja.md)が公開されているので参照してください。
|
|
|
|
|
|
|
|
|
|
|
|
# 起動まで
|
|
|
|
|
|
## HuBERTのインストール
|
|
|
|
|
|
RVCの実行にはHuBERTが必要です。
|
|
|
|
|
|
[このリポジトリ](https://huggingface.co/lj1995/VoiceConversionWebUI/tree/main)から`hubert_base.pt`をダウンロードして、バッチファイルがあるフォルダに格納してください。
|
|
|
|
|
|
|
|
|
|
|
|
## GUIの起動
|
|
|
|
|
|
### Windows 版、
|
|
|
|
|
|
ダウンロードした zip ファイルを解凍して、`start_http.bat`を実行してください。
|
|
|
|
|
|
|
|
|
|
|
|
### Mac 版
|
|
|
|
|
|
ダウンロードファイルを解凍したのちに、`startHttp.command`を実行してください。開発元を検証できない旨が示される場合は、再度コントロールキーを押してクリックして実行してください(or 右クリックから実行してください)。
|
|
|
|
|
|
|
|
|
|
|
|
### リモート接続時の注意
|
|
|
|
|
|
リモートから接続する場合は、`.bat`ファイル(win)、`.command`ファイル(mac)の http が https に置き換わっているものを使用してください。
|
|
|
|
|
|
|
|
|
|
|
|
## クライアントの選択
|
|
|
|
|
|
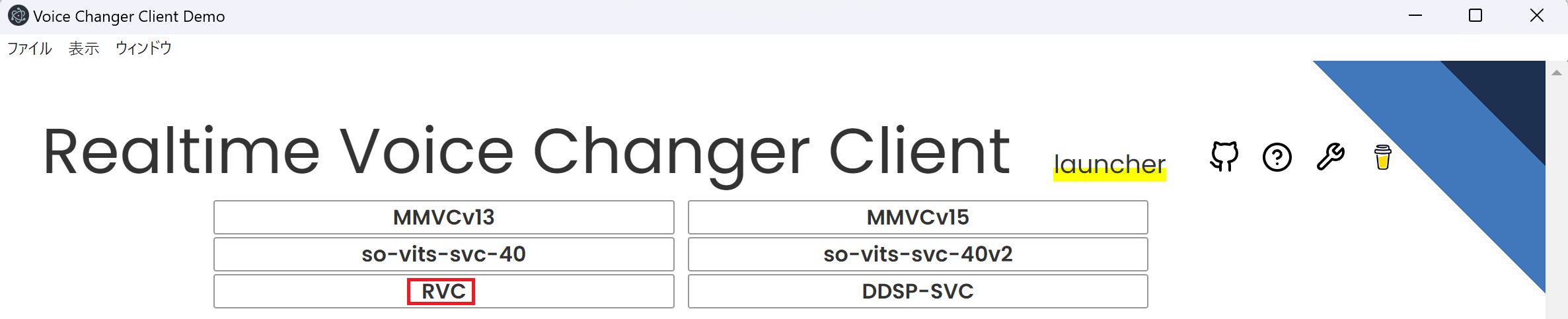
下記のようなLauncher画面が出れば成功です。この画面からRVCを選択してください。
|
|
|
|
|
|
|
2023-04-28 14:07:58 +03:00
|
|
|
|
|
|
|
|
|
|
|
2023-04-24 03:06:28 +03:00
|
|
|
|
|
|
|
|
|
|
## RVC用の画面
|
|
|
|
|
|
下記のような画面が出れば成功です。右上の?ボタンから[マニュアル](https://zenn.dev/wok/books/0004_vc-client-v_1_5_1_x)に移動できます。
|
|
|
|
|
|
|
2023-04-28 14:07:58 +03:00
|
|
|
|

|
2023-04-24 03:06:28 +03:00
|
|
|
|
|
|
|
|
|
|
# クイックスタート
|
|
|
|
|
|
日本語版では[マニュアル](https://zenn.dev/wok/books/0004_vc-client-v_1_5_1_x/viewer/003-1_quick-start)が用意されているのでこちらを参照してください。
|
|
|
|
|
|
|
|
|
|
|
|
## GUIの項目の詳細
|
|
|
|
|
|
## server control
|
|
|
|
|
|
### start
|
2023-04-25 16:03:16 +03:00
|
|
|
|
startでサーバーを起動、stopでサーバーを停止します
|
2023-04-24 03:06:28 +03:00
|
|
|
|
|
|
|
|
|
|
### monitor
|
|
|
|
|
|
リアルタイム変換の状況を示します。
|
|
|
|
|
|
|
2023-04-25 16:03:16 +03:00
|
|
|
|
声を出してから変換までのラグは`buf + res秒`です。調整の際はbufの時間がresよりも長くなるように調整してください。
|
2023-04-24 03:06:28 +03:00
|
|
|
|
|
|
|
|
|
|
#### vol
|
|
|
|
|
|
音声変換後の音量です。
|
|
|
|
|
|
|
|
|
|
|
|
#### buf
|
|
|
|
|
|
音声を切り取る一回の区間の長さ(ms)です。Input Chunkを短くするとこの数値が減ります。
|
|
|
|
|
|
|
|
|
|
|
|
#### res
|
|
|
|
|
|
Input ChunkとExtra Data Lengthを足したデータを変換にかかる時間です。Input ChunkとExtra Data Lengthのいずれでも短くすると数値が減ります。
|
|
|
|
|
|
|
|
|
|
|
|
### Model Info
|
|
|
|
|
|
サーバが保持している情報を取得します。サーバ・クライアント間で情報同期がうまくいってなさそうなときReloadボタンを押してみてください。
|
|
|
|
|
|
|
|
|
|
|
|
### Switch Model
|
|
|
|
|
|
アップロードしたモデルについて切り替えることができます。
|
2023-04-26 17:34:12 +03:00
|
|
|
|
モデルについては名前の下に[]で情報が示されます
|
|
|
|
|
|
1. f0(=pitch)を考慮するモデルか
|
|
|
|
|
|
- f0: 考慮する
|
|
|
|
|
|
- nof0: 考慮しない
|
|
|
|
|
|
2. モデルの学習に用いられたサンプリングレート
|
|
|
|
|
|
3. モデルが用いる特徴量のチャンネル数(大きいほど情報を持っていて重い)
|
|
|
|
|
|
4. 学習に用いられたクライアント
|
|
|
|
|
|
- org: [本家RVC](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI)で学習したモデルです。
|
2023-04-28 14:07:58 +03:00
|
|
|
|
- webui:[ddPn08RVC](https://github.com/ddPn08/rvc-webui)で学習したモデルです。
|
2023-04-26 17:34:12 +03:00
|
|
|
|
|
|
|
|
|
|
### EXPORT ONNX
|
|
|
|
|
|
ONNXモデルを出力します。PyTorchのモデルをONNXモデルに変換すると、推論が高速化される場合があります。
|
2023-04-24 03:06:28 +03:00
|
|
|
|
|
|
|
|
|
|
## Model Setting
|
|
|
|
|
|
### Model Uploader
|
2023-04-29 01:34:01 +03:00
|
|
|
|
Slot毎にPyTorchかONNXのどちらかのみ選べます。
|
2023-04-24 03:06:28 +03:00
|
|
|
|
|
|
|
|
|
|
#### Model Slot
|
|
|
|
|
|
モデルをどの枠にセットするか選べます。セットしたモデルはServer ControlのSwitch Modelで切り替えられます。
|
|
|
|
|
|
|
2023-04-26 17:34:12 +03:00
|
|
|
|
#### Model(.onnx or .pth)
|
|
|
|
|
|
学習済みモデルをここで指定します。必須項目です。
|
|
|
|
|
|
ONNX形式(.onnx)かPyTorch形式(.pth)のいずれかを選択可能です。
|
2023-04-24 03:06:28 +03:00
|
|
|
|
|
2023-04-29 01:34:01 +03:00
|
|
|
|
- [orginal-RVC](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI)で学習させた場合、`/logs/weights`に入っています。
|
|
|
|
|
|
- [ddPn08RVC](https://github.com/ddPn08/rvc-webui)で学習させた場合、`/models/checkpoints`に入っています。
|
2023-04-24 03:06:28 +03:00
|
|
|
|
|
|
|
|
|
|
#### feature(.npy)
|
|
|
|
|
|
HuBERTで抽出した特徴を訓練データに近づける追加機能です。index(.index)とペアで使用します。
|
2023-04-29 01:34:01 +03:00
|
|
|
|
|
|
|
|
|
|
- [orginal-RVC](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI)で学習させた場合、`/logs/実験名/total_fea.npy`という名前で保存されています。(2023/04/26にtotal_fea.npyを省略するアップデートが入ったので今後不要になる可能性があります)
|
|
|
|
|
|
- [ddPn08RVC](https://github.com/ddPn08/rvc-webui)で学習させた場合、`/models/checkpoints/モデル名_index/モデル名.0.big.npy`という名前で保存されています。
|
2023-04-24 03:06:28 +03:00
|
|
|
|
|
|
|
|
|
|
#### index(.index)
|
|
|
|
|
|
HuBERTで抽出した特徴を訓練データに近づける追加機能です。feature(.npy)とペアで使用します。
|
2023-04-29 01:34:01 +03:00
|
|
|
|
|
|
|
|
|
|
- [orginal-RVC](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI)で学習させた場合、`/logs/実験名/add_XXX.index`という名前で保存されています。
|
|
|
|
|
|
- [ddPn08RVC](https://github.com/ddPn08/rvc-webui)で学習させた場合、`/models/checkpoints/モデル名_index/モデル名.0.index`という名前で保存されています。
|
2023-04-24 03:06:28 +03:00
|
|
|
|
|
|
|
|
|
|
#### half-precision
|
|
|
|
|
|
精度をfloat32かfloat16のどちらで推論するか選べます。
|
|
|
|
|
|
これを選択すると精度を犠牲に高速化できます。
|
|
|
|
|
|
上手く動かない場合はオフにしてください。
|
|
|
|
|
|
|
|
|
|
|
|
#### Default Tune
|
|
|
|
|
|
声のピッチをどれくらい変換するかデフォルトの値を入れます。推論中に変換もできます。以下は設定の目安です。
|
|
|
|
|
|
|
|
|
|
|
|
- 男声→女声 の変換では+12
|
|
|
|
|
|
- 女声→男声 の変換では-12
|
|
|
|
|
|
|
|
|
|
|
|
#### upload
|
|
|
|
|
|
上記の項目を設定した後、押すとmodelを使用できる状態にします。
|
|
|
|
|
|
|
|
|
|
|
|
## Device Setting
|
|
|
|
|
|
### AudioInput
|
|
|
|
|
|
入力端末を選びます
|
|
|
|
|
|
|
|
|
|
|
|
### AudioOutput
|
|
|
|
|
|
出力端末を選びます
|
|
|
|
|
|
|
|
|
|
|
|
#### output record
|
|
|
|
|
|
startをおしてからstopを押すまでの音声が記録されます。
|
|
|
|
|
|
このボタンを押してもリアルタイム変換は始まりません。
|
|
|
|
|
|
リアルタイム変換はServer Controlを押してください
|
|
|
|
|
|
|
|
|
|
|
|
## Quality Control
|
|
|
|
|
|
|
|
|
|
|
|
### Noise Supression
|
|
|
|
|
|
ブラウザ組み込みのノイズ除去機能のOn/Offです。
|
|
|
|
|
|
|
|
|
|
|
|
### Gain Control
|
|
|
|
|
|
- input:モデルへの入力音声の音量を増減します。1がデフォルト
|
|
|
|
|
|
- output:モデルからの出力音声の音量を増減します。1がデフォルト
|
|
|
|
|
|
|
|
|
|
|
|
### F0Detector
|
|
|
|
|
|
ピッチを抽出するためのアルゴリズムを選びます。以下の二種類を選べます。
|
|
|
|
|
|
|
|
|
|
|
|
- 軽量な`pm`
|
|
|
|
|
|
- 高精度な`harvest`
|
|
|
|
|
|
|
|
|
|
|
|
### Analyzer(Experimental)
|
|
|
|
|
|
サーバ側で入力と出力を録音します。
|
|
|
|
|
|
入力はマイクの音声がサーバに送られて、それがそのまま録音されます。マイク⇒サーバの通信路の確認に使えます。
|
|
|
|
|
|
出力はモデルから出力されるデータがサーバ内で録音されます。(入力が正しいことが確認できたうえで)モデルの動作を確認できます。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
## Speaker Setting
|
|
|
|
|
|
### Destination Speaker Id
|
2023-04-28 14:07:58 +03:00
|
|
|
|
複数話者に対応した時の設定かと思われますが、[本家RVC](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI)が対応していないので現状は使わない項目です。
|
2023-04-24 03:06:28 +03:00
|
|
|
|
|
|
|
|
|
|
### Tuning
|
|
|
|
|
|
声のピッチを調整します。以下は設定の目安です。
|
|
|
|
|
|
|
|
|
|
|
|
- 男声→女声 の変換では+12
|
|
|
|
|
|
- 女声→男声 の変換では-12
|
|
|
|
|
|
|
|
|
|
|
|
### index ratio
|
|
|
|
|
|
学習で使用した特徴量に寄せる比率を指定します。Model Settingでfeatureとindexを両方設定した時に有効です。
|
|
|
|
|
|
0でHuBERTの出力をそのまま使う、1で元の特徴量にすべて寄せます。
|
|
|
|
|
|
index ratioが0より大きいと検索に時間がかかる場合があります。
|
|
|
|
|
|
|
|
|
|
|
|
### Silent Threshold
|
|
|
|
|
|
音声変換を行う音量の閾地です。この値より小さいrmsの時は音声変換をせず無音を返します。
|
|
|
|
|
|
(この場合、変換処理がスキップされるので、あまり負荷がかかりません。)
|
|
|
|
|
|
|
|
|
|
|
|
## Converter Setting
|
|
|
|
|
|
### InputChunk Num(128sample / chunk)
|
|
|
|
|
|
一度の変換でどれくらいの長さを切り取って変換するかを決めます。これが大きいほど効率的に変換できますが、bufの値が大きくなり変換が開始されるまでの最大の時間が伸びます。 buff: におよその時間が表示されます。
|
|
|
|
|
|
|
|
|
|
|
|
### Extra Data Length
|
|
|
|
|
|
音声を変換する際、入力にどれくらいの長さの過去の音声を入れるかを決めます。過去の音声が長く入っているほど変換の精度はよくなりますが、その分計算に時間がかかるためresが長くなります。
|
|
|
|
|
|
(おそらくTransformerがネックなので、これの長さの2乗で計算時間は増えます)
|
|
|
|
|
|
|
|
|
|
|
|
### GPU
|
|
|
|
|
|
GPUを2枚以上持っている場合、ここでGPUを選べます。
|