mirror of
https://github.com/w-okada/voice-changer.git
synced 2025-02-02 16:23:58 +03:00
Merge branch 'master' into v.1.5.3
This commit is contained in:
commit
3512bbb1eb
1
.github/ISSUE_TEMPLATE/issue.yaml
vendored
1
.github/ISSUE_TEMPLATE/issue.yaml
vendored
@ -1,7 +1,6 @@
|
||||
name: Issue or Bug Report
|
||||
description: Please provide as much detail as possible to convey the history of your problem.
|
||||
title: "[ISSUE]: "
|
||||
placeholder: "[ISSUE]: Please provide title"
|
||||
body:
|
||||
- type: markdown
|
||||
attributes:
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
## VC Client
|
||||
|
||||
[English](/README_en.md)
|
||||
[English](/README_en.md) [Korean](/README_ko.md)
|
||||
|
||||
## What's New!
|
||||
- v.1.5.3.16 (Only for Windows, CPU dependent)
|
||||
@ -10,7 +10,7 @@
|
||||
- v.1.5.3.15
|
||||
- Improve:
|
||||
- new rmvpe checkpoint for rvc (torch, onnx)
|
||||
- Mac: upgrad torch version 2.1.0
|
||||
- Mac: upgrade torch version 2.1.0
|
||||
|
||||
- v.1.5.3.14
|
||||
- Improve:
|
||||
|
||||
122
README_dev_ko.md
Normal file
122
README_dev_ko.md
Normal file
@ -0,0 +1,122 @@
|
||||
## 개발자용
|
||||
|
||||
[English](/README_dev_en.md) [Korean](/README_dev_ko.md)
|
||||
|
||||
## 전제
|
||||
|
||||
- Linux(ubuntu, debian) or WSL2, (다른 리눅스 배포판과 Mac에서는 테스트하지 않았습니다)
|
||||
- Anaconda
|
||||
|
||||
## 준비
|
||||
|
||||
1. Anaconda 가상 환경을 작성한다
|
||||
|
||||
```
|
||||
$ conda create -n vcclient-dev python=3.10
|
||||
$ conda activate vcclient-dev
|
||||
```
|
||||
|
||||
2. 리포지토리를 클론한다
|
||||
|
||||
```
|
||||
$ git clone https://github.com/w-okada/voice-changer.git
|
||||
```
|
||||
|
||||
## 서버 개발자용
|
||||
|
||||
1. 모듈을 설치한다
|
||||
|
||||
```
|
||||
$ cd voice-changer/server
|
||||
$ pip install -r requirements.txt
|
||||
```
|
||||
|
||||
2. 서버를 구동한다
|
||||
|
||||
다음 명령어로 구동합니다. 여러 가중치에 대한 경로는 환경에 맞게 변경하세요.
|
||||
|
||||
```
|
||||
$ python3 MMVCServerSIO.py -p 18888 --https true \
|
||||
--content_vec_500 pretrain/checkpoint_best_legacy_500.pt \
|
||||
--content_vec_500_onnx pretrain/content_vec_500.onnx \
|
||||
--content_vec_500_onnx_on true \
|
||||
--hubert_base pretrain/hubert_base.pt \
|
||||
--hubert_base_jp pretrain/rinna_hubert_base_jp.pt \
|
||||
--hubert_soft pretrain/hubert/hubert-soft-0d54a1f4.pt \
|
||||
--nsf_hifigan pretrain/nsf_hifigan/model \
|
||||
--crepe_onnx_full pretrain/crepe_onnx_full.onnx \
|
||||
--crepe_onnx_tiny pretrain/crepe_onnx_tiny.onnx \
|
||||
--rmvpe pretrain/rmvpe.pt \
|
||||
--model_dir model_dir \
|
||||
--samples samples.json
|
||||
```
|
||||
|
||||
브라우저(Chrome에서만 지원)에서 접속하면 화면이 나옵니다.
|
||||
|
||||
2-1. 문제 해결법
|
||||
|
||||
(1) OSError: PortAudio library not found
|
||||
다음과 같은 메시지가 나올 경우에는 추가 라이브러리를 설치해야 합니다.
|
||||
|
||||
```
|
||||
OSError: PortAudio library not found
|
||||
```
|
||||
|
||||
ubuntu(wsl2)인 경우에는 아래 명령어로 설치할 수 있습니다.
|
||||
|
||||
```
|
||||
$ sudo apt-get install libportaudio2
|
||||
$ sudo apt-get install libasound-dev
|
||||
```
|
||||
|
||||
(2) 서버 구동이 안 되는데요?!
|
||||
|
||||
클라이언트는 자동으로 구동되지 않습니다. 브라우저를 실행하고 콘솔에 표시된 URL로 접속하세요.
|
||||
|
||||
(3) Could not load library libcudnn_cnn_infer.so.8
|
||||
WSL를 사용 중이라면 `Could not load library libcudnn_cnn_infer.so.8. Error: libcuda.so: cannot open shared object file: No such file or directory`라는 메시지가 나오는 경우가 있습니다.
|
||||
잘못된 경로가 원인인 경우가 많습니다. 아래와 같이 경로를 바꾸고 실행해 보세요.
|
||||
.bashrc 등 구동 스크립트에 추가해 두면 편리합니다.
|
||||
|
||||
```
|
||||
export LD_LIBRARY_PATH=/usr/lib/wsl/lib:$LD_LIBRARY_PATH
|
||||
```
|
||||
|
||||
- 참고
|
||||
- https://qiita.com/cacaoMath/items/811146342946cdde5b83
|
||||
- https://github.com/microsoft/WSL/issues/8587
|
||||
|
||||
3. 개발하세요
|
||||
|
||||
### Appendix
|
||||
|
||||
1. Win + Anaconda일 때 (not supported)
|
||||
|
||||
pytorch를 conda가 없으면 gpu를 인식하지 않을 수 있습니다.
|
||||
|
||||
```
|
||||
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
|
||||
```
|
||||
|
||||
또한 추가로 아래 내용도 필요합니다.
|
||||
|
||||
```
|
||||
pip install chardet
|
||||
pip install numpy==1.24.0
|
||||
```
|
||||
|
||||
## 클라이언트 개발자용
|
||||
|
||||
1. 모듈을 설치하고 한번 빌드합니다
|
||||
|
||||
```
|
||||
cd client
|
||||
cd lib
|
||||
npm install
|
||||
npm run build:dev
|
||||
cd ../demo
|
||||
npm install
|
||||
npm run build:dev
|
||||
```
|
||||
|
||||
2. 개발하세요
|
||||
@ -1,6 +1,6 @@
|
||||
## VC Client
|
||||
|
||||
[Japanese](/README_ja.md)
|
||||
[Japanese](/README_ja.md) [Korean](/README_ko.md)
|
||||
|
||||
## What's New!
|
||||
|
||||
@ -11,7 +11,7 @@
|
||||
- v.1.5.3.15
|
||||
- Improve:
|
||||
- new rmvpe checkpoint for rvc (torch, onnx)
|
||||
- Mac: upgrad torch version 2.1.0
|
||||
- Mac: upgrade torch version 2.1.0
|
||||
|
||||
- v.1.5.3.14
|
||||
- Improve:
|
||||
|
||||
193
README_ko.md
Normal file
193
README_ko.md
Normal file
@ -0,0 +1,193 @@
|
||||
## VC Client
|
||||
|
||||
[English](/README_en.md) [Korean](/README_ko.md)
|
||||
|
||||
## 새로운 기능!
|
||||
- v.1.5.3.15
|
||||
- Improve:
|
||||
- new rmvpe checkpoint for rvc (torch, onnx)
|
||||
- Mac: upgrade torch version 2.1.0
|
||||
|
||||
- v.1.5.3.14
|
||||
- Improve:
|
||||
- onnx performance (need to be converted)
|
||||
- Some fixes:
|
||||
- change default f0 det to onnx_rmvpe
|
||||
- disable unrecommnded f0 det on direct ml
|
||||
- Experimental
|
||||
- Add 16k RVC Sample (experimental)
|
||||
|
||||
|
||||
|
||||
# VC Client란
|
||||
|
||||
1. 각종 음성 변환 AI(VC, Voice Conversion)를 활용해 실시간 음성 변환을 하기 위한 클라이언트 소프트웨어입니다. 지원하는 음성 변환 AI는 다음과 같습니다.
|
||||
|
||||
- 지원하는 음성 변환 AI (지원 VC)
|
||||
- [MMVC](https://github.com/isletennos/MMVC_Trainer)
|
||||
- [so-vits-svc](https://github.com/svc-develop-team/so-vits-svc)
|
||||
- [RVC(Retrieval-based-Voice-Conversion)](https://github.com/liujing04/Retrieval-based-Voice-Conversion-WebUI)
|
||||
- [DDSP-SVC](https://github.com/yxlllc/DDSP-SVC)
|
||||
|
||||
2. 이 소프트웨어는 네트워크를 통한 사용도 가능하며, 게임 등 부하가 큰 애플리케이션과 동시에 사용할 경우 음성 변화 처리의 부하를 외부로 돌릴 수도 있습니다.
|
||||
|
||||

|
||||
|
||||
3. 여러 플랫폼을 지원합니다.
|
||||
|
||||
- Windows, Mac(M1), Linux, Google Colab (MMVC만 지원)
|
||||
|
||||
# 사용 방법
|
||||
|
||||
크게 두 가지 방법으로 사용할 수 있습니다. 난이도 순서는 다음과 같습니다.
|
||||
|
||||
- 사전 빌드된 Binary 사용
|
||||
- Docker, Anaconda 등으로 구축된 개발 환경에서 사용
|
||||
|
||||
이 소프트웨어나 MMVC에 익숙하지 않은 분들은 위에서부터 차근차근 익숙해지길 추천합니다.
|
||||
|
||||
## (1) 사전 빌드된 Binary(파일) 사용
|
||||
|
||||
- 실행 형식 바이너리를 다운로드하여 실행할 수 있습니다.
|
||||
|
||||
- 튜토리얼은 [이곳](tutorials/tutorial_rvc_ko_latest.md)을 확인하세요。([네트워크 문제 해결법](https://github.com/w-okada/voice-changer/blob/master/tutorials/trouble_shoot_communication_ko.md))
|
||||
|
||||
- [Google Colaboratory](https://github.com/w-okada/voice-changer/blob/master/Realtime_Voice_Changer_on_Colab.ipynb) で簡単にお試しいただけるようになりました。左上の Open in Colab のボタンから起動できます。
|
||||
|
||||
<img src="https://github.com/w-okada/voice-changer/assets/48346627/3f092e2d-6834-42f6-bbfd-7d389111604e" width="400" height="150">
|
||||
|
||||
- Windows 버전과 Mac 버전을 제공하고 있습니다.
|
||||
|
||||
- Windows와 NVIDIA GPU를 사용하는 분은 ONNX(cpu, cuda), PyTorch(cpu, cuda)를 다운로드하세요.
|
||||
- Windows와 AMD/Intel GPU를 사용하는 분은 ONNX(cpu, DirectML), PyTorch(cpu, cuda)를 다운로드하세요 AMD/Intel GPU는 ONNX 모델을 사용할 때만 적용됩니다.
|
||||
- 그 외 GPU도 PyTorch, Onnxruntime가 지원할 경우에만 적용됩니다.
|
||||
- Windows에서 GPU를 사용하지 않는 분은 ONNX(cpu, cuda), PyTorch(cpu, cuda)를 다운로드하세요.
|
||||
|
||||
- Windows 버전은 다운로드한 zip 파일의 압축을 풀고 `start_http.bat`를 실행하세요.
|
||||
|
||||
- Mac 버전은 다운로드한 파일을 풀고 `startHttp.command`를 실행하세요. 확인되지 않은 개발자 메시지가 나오면 다시 control 키를 누르고 클릭해 실행하세요(or 오른쪽 클릭으로 실행하세요).
|
||||
|
||||
- 처음 실행할 때는 인터넷으로 여러 데이터를 다운로드합니다. 다운로드할 때 시간이 좀 걸릴 수 있습니다. 다운로드가 완료되면 브라우저가 실행됩니다.
|
||||
|
||||
- 원격으로 접속할 때는 http 대신 https `.bat` 파일(win)、`.command` 파일(mac)을 실행하세요.
|
||||
|
||||
- DDPS-SVC의 encoder는 hubert-soft만 지원합니다.
|
||||
|
||||
- 다운로드는 아래에서 하세요.
|
||||
|
||||
| Version | OS | 프레임워크 | 링크 | 지원 VC | 파일 크기 |
|
||||
| ---------- | --- | ------------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------- | ------ |
|
||||
| v.1.5.3.15 | mac | ONNX(cpu), PyTorch(cpu,mps) | [hugging face](https://huggingface.co/wok000/vcclient000/tree/main) | MMVC v.1.5.x, MMVC v.1.3.x, so-vits-svc 4.0, RVC | 797MB |
|
||||
| | win | ONNX(cpu,cuda), PyTorch(cpu,cuda) | [hugging face](https://huggingface.co/wok000/vcclient000/tree/main) | MMVC v.1.5.x, MMVC v.1.3.x, so-vits-svc 4.0, RVC, DDSP-SVC, Diffusion-SVC | 3240MB |
|
||||
| | win | ONNX(cpu,DirectML), PyTorch(cpu,cuda) | [hugging face](https://huggingface.co/wok000/vcclient000/tree/main) | MMVC v.1.5.x, MMVC v.1.3.x, so-vits-svc 4.0, RVC, DDSP-SVC, Diffusion-SVC | 3125MB |
|
||||
| v.1.5.3.14 | mac | ONNX(cpu), PyTorch(cpu,mps) | [hugging face](https://huggingface.co/wok000/vcclient000/tree/main) | MMVC v.1.5.x, MMVC v.1.3.x, so-vits-svc 4.0, RVC | 797MB |
|
||||
| | win | ONNX(cpu,cuda), PyTorch(cpu,cuda) | [hugging face](https://huggingface.co/wok000/vcclient000/tree/main) | MMVC v.1.5.x, MMVC v.1.3.x, so-vits-svc 4.0, RVC, DDSP-SVC, Diffusion-SVC | 3240MB |
|
||||
| | win | ONNX(cpu,DirectML), PyTorch(cpu,cuda) | [hugging face](https://huggingface.co/wok000/vcclient000/tree/main) | MMVC v.1.5.x, MMVC v.1.3.x, so-vits-svc 4.0, RVC, DDSP-SVC, Diffusion-SVC | 3125MB |
|
||||
|
||||
(\*1) Google Drive에서 다운로드가 안 되는 분은 [hugging_face](https://huggingface.co/wok000/vcclient000/tree/main)에서 시도해 보세요
|
||||
(\*2) 개발자가 AMD 그래픽카드를 갖고 있지 않아서 작동 확인을 할 수 없습니다. onnxruntime-directml를 같이 첨부한 것이 전부입니다.
|
||||
(\*3) 압축 해제나 실행 속도가 느릴 경우에는 바이러스 검사가 진행 중일 가능성이 있습니다. 파일과 폴더를 검사 대상 제외를 한 후에 시도해 보세요. (이에 개발자는 책임이 없음)
|
||||
|
||||
## (2) Docker나 Anaconda 등으로 구축된 개발 환경에서 사용
|
||||
|
||||
이 리포지토리를 클론해 사용할 수 있습니다. Windows에서는 WSL2 환경 구축이 필수입니다. 또한, WSL2 상에 Docker나 Anaconda 등의 가상환경 구축이 필요합니다. Mac에서는 Anaconda 등의 Python 가상환경 구축이 필요합니다. 사전 준비가 필요하지만, 많은 환경에서 이 방법이 가장 빠르게 작동합니다. **<font color="red"> GPU가 없어도 나름 최근 출시된 CPU가 있다면 충분히 작동할 가능성이 있습니다</font>(아래 실시간성 항목 참조)**.
|
||||
|
||||
[WSL2와 Docker 설치 설명 영상](https://youtu.be/POo_Cg0eFMU)
|
||||
|
||||
[WSL2와 Anaconda 설치 설명 영상](https://youtu.be/fba9Zhsukqw)
|
||||
|
||||
Docker에서 실행은 [Docker를 사용](docker_vcclient/README_ko.md)을 참고해 서버를 구동하세요.
|
||||
|
||||
Anaconda 가상 환경에서 실행은 [서버 개발자용 문서](README_dev_ko.md)를 참고해 서버를 구동하세요.
|
||||
|
||||
# 문제 해결법
|
||||
|
||||
- [통신편](tutorials/trouble_shoot_communication_ko.md)
|
||||
|
||||
# 실시간성(MMVC)
|
||||
|
||||
GPU를 사용하면 시간 차가 거의 없이 변환할 수 있습니다.
|
||||
|
||||
https://twitter.com/DannadoriYellow/status/1613483372579545088?s=20&t=7CLD79h1F3dfKiTb7M8RUQ
|
||||
|
||||
CPU도 최근 제품이라면 어느 정도 빠르게 변환할 수 있습니다.
|
||||
|
||||
https://twitter.com/DannadoriYellow/status/1613553862773997569?s=20&t=7CLD79h1F3dfKiTb7M8RUQ
|
||||
|
||||
오래된 CPU(i7-4770)면, 1000msec 정도 걸립니다.
|
||||
|
||||
# 개발자 서명에 대하여
|
||||
|
||||
이 소프트웨어는 개발자 서명이 없습니다. 本ソフトウェアは開発元の署名しておりません。下記のように警告が出ますが、コントロールキーを押しながらアイコンをクリックすると実行できるようになります。これは Apple のセキュリティポリシーによるものです。実行は自己責任となります。
|
||||
|
||||

|
||||
(이미지 번역: ctrl을 누른 채로 클릭)
|
||||
|
||||
# 감사의 말
|
||||
|
||||
- [立ちずんだもん素材](https://seiga.nicovideo.jp/seiga/im10792934)
|
||||
- [いらすとや](https://www.irasutoya.com/)
|
||||
- [つくよみちゃん](https://tyc.rei-yumesaki.net/)
|
||||
|
||||
```
|
||||
이 소프트웨어의 음성 합성에는 무료 소재 캐릭터 「つくよみちゃん(츠쿠요미 짱)」이 무료 공개하고 있는 음성 데이터를 사용했습니다.■츠쿠요미 짱 말뭉치(CV.夢前黎)
|
||||
https://tyc.rei-yumesaki.net/material/corpus/
|
||||
© Rei Yumesaki
|
||||
```
|
||||
|
||||
- [あみたろの声素材工房](https://amitaro.net/)
|
||||
- [れぷりかどーる](https://kikyohiroto1227.wixsite.com/kikoto-utau)
|
||||
|
||||
# 이용약관
|
||||
|
||||
- 실시간 음성 변환기 츠쿠요미 짱은 츠쿠요미 짱 말뭉치 이용약관에 따라 다음과 같은 목적으로 변환 후 음성을 사용하는 것을 금지합니다.
|
||||
|
||||
```
|
||||
|
||||
■사람을 비판·공격하는 행위. ("비판·공격"의 정의는 츠쿠요미 짱 캐릭터 라이센스에 준합니다)
|
||||
|
||||
■특정 정치적 입장·종교·사상에 대한 찬반을 논하는 행위.
|
||||
|
||||
■자극적인 표현물을 무분별하게 공개하는 행위.
|
||||
|
||||
■타인에게 2차 창작(소재로서의 활용)을 허가하는 형태로 공개하는 행위.
|
||||
※감상용 작품으로서 배포·판매하는 건 문제없습니다.
|
||||
```
|
||||
|
||||
- 실시간 음성 변환기 아미타로는 あみたろの声素材工房(아미타로의 음성 소재 공방)의 다음 이용약관에 따릅니다. 자세한 내용은 [이곳](https://amitaro.net/voice/faq/#index_id6)에 있습니다.
|
||||
|
||||
```
|
||||
아미타로의 음성 소재나 말뭉치 음성으로 음성 모델을 만들거나, 음성 변환기나 말투 변환기 등을 사용해 본인 목소리를 아미타로의 목소리로 변환해 사용하는 것도 괜찮습니다.
|
||||
|
||||
단, 그 경우에는 반드시 아미타로(혹은 코하루네 아미)의 음성으로 변환한 것을 명시하고, 아미타로(및 코하루네 아미)가 말하는 것이 아님을 누구나 알 수 있도록 하십시오.
|
||||
또한 아미타로의 음성으로 말하는 내용은 음성 소재 이용약관의 범위 내에서만 사용해야 하며, 민감한 발언은 삼가십시오.
|
||||
```
|
||||
|
||||
- 실시간 음성 변환기 키코토 마히로는 れぷりかどーる(레플리카 돌)의 이용약관에 따릅니다. 자세한 내용은 [이곳](https://kikyohiroto1227.wixsite.com/kikoto-utau/ter%EF%BD%8Ds-of-service)에 있습니다.
|
||||
|
||||
# 면책 사항
|
||||
|
||||
이 소프트웨어의 사용 또는 사용 불능으로 인해 발생한 직접 손해·간접 손해·파생적 손해·결과적 손해 또는 특별 손해에 대해 모든 책임을 지지 않습니다.
|
||||
|
||||
# (1) 레코더(트레이닝용 음성 녹음 앱)
|
||||
|
||||
MMVC 트레이닝용 음성을 간단하게 녹음할 수 있는 앱입니다.
|
||||
Github Pages에서 실행할 수 있어서 브라우저만 있으면 다양한 플랫폼에서 사용할 수 있습니다.
|
||||
녹음한 데이터는 브라우저에 저장됩니다. 외부로 유출되지 않습니다.
|
||||
|
||||
[녹음 앱 on Github Pages](https://w-okada.github.io/voice-changer/)
|
||||
|
||||
[설명 영상](https://youtu.be/s_GirFEGvaA)
|
||||
|
||||
# 이전 버전
|
||||
|
||||
| Version | OS | 프레임워크 | link | 지원 VC | 파일 크기 |
|
||||
| ---------- | --- | --------------------------------- | ---------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------- | ------ |
|
||||
| v.1.5.2.9e | mac | ONNX(cpu), PyTorch(cpu,mps) | [normal](https://drive.google.com/uc?id=1W0d7I7619PcO7kjb1SPXp6MmH5Unvd78&export=download) \*1 | MMVC v.1.5.x, MMVC v.1.3.x, so-vits-svc 4.0, RVC | 796MB |
|
||||
| | win | ONNX(cpu,cuda), PyTorch(cpu,cuda) | [normal](https://drive.google.com/uc?id=1tmTMJRRggS2Sb4goU-eHlRvUBR88RZDl&export=download) \*1 | MMVC v.1.5.x, MMVC v.1.3.x, so-vits-svc 4.0, so-vits-svc 4.0v2, RVC, DDSP-SVC | 2872MB |
|
||||
| v.1.5.3.1 | mac | ONNX(cpu), PyTorch(cpu,mps) | [normal](https://drive.google.com/uc?id=1oswF72q_cQQeXhIn6W275qLnoBAmcrR_&export=download) \*1 | MMVC v.1.5.x, MMVC v.1.3.x, so-vits-svc 4.0, RVC | 796MB |
|
||||
| | win | ONNX(cpu,cuda), PyTorch(cpu,cuda) | [normal](https://drive.google.com/uc?id=1AWjDhW4w2Uljp1-9P8YUJBZsIlnhkJX2&export=download) \*1 | MMVC v.1.5.x, MMVC v.1.3.x, so-vits-svc 4.0, so-vits-svc 4.0v2, RVC, DDSP-SVC | 2872MB |
|
||||
|
||||
# For Contributor
|
||||
|
||||
이 리포지토리는 [CLA](https://raw.githubusercontent.com/w-okada/voice-changer/master/LICENSE-CLA)를 설정했습니다.
|
||||
@ -1,6 +1,6 @@
|
||||
## VC Client for Docker
|
||||
|
||||
[English](./README_en.md)
|
||||
[English](./README_en.md) [Korean](./README_ko.md)
|
||||
|
||||
## ビルド
|
||||
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
## VC Client for Docker
|
||||
|
||||
[Japanese](./README.md)
|
||||
[Japanese](./README.md)
|
||||
[Korean](./README.md)
|
||||
|
||||
## Build
|
||||
|
||||
|
||||
47
docker_vcclient/README_ko.md
Normal file
47
docker_vcclient/README_ko.md
Normal file
@ -0,0 +1,47 @@
|
||||
## VC Client for Docker
|
||||
|
||||
[Japanese](./README.md) [English](./README_en.md)
|
||||
|
||||
## 빌드
|
||||
|
||||
리포지토리 폴더의 최상위 위치에서
|
||||
|
||||
```
|
||||
npm run build:docker:vcclient
|
||||
```
|
||||
|
||||
## 실행
|
||||
|
||||
리포지토리 폴더의 최상위 위치에서
|
||||
|
||||
```
|
||||
bash start_docker.sh
|
||||
```
|
||||
|
||||
브라우저(Chrome에서만 지원)로 접속하면 화면이 나옵니다.
|
||||
|
||||
## RUN with options
|
||||
|
||||
GPU를 사용하지 않는 경우에는
|
||||
|
||||
```
|
||||
USE_GPU=off bash start_docker.sh
|
||||
```
|
||||
|
||||
포트 번호를 변경하고 싶은 경우에는
|
||||
|
||||
```
|
||||
EX_PORT=<port> bash start_docker.sh
|
||||
```
|
||||
|
||||
로컬 이미지를 사용하고 싶은 경우에는
|
||||
|
||||
```
|
||||
USE_LOCAL=on bash start_docker.sh
|
||||
```
|
||||
|
||||
## Push to Repo (only for devs)
|
||||
|
||||
```
|
||||
npm run push:docker:vcclient
|
||||
```
|
||||
@ -63,6 +63,14 @@
|
||||
"created_at": "2023-09-26T16:38:25Z",
|
||||
"repoId": 527419347,
|
||||
"pullRequestNo": 892
|
||||
},
|
||||
{
|
||||
"name": "qlife1146",
|
||||
"id": 32091837,
|
||||
"comment_id": 1789932002,
|
||||
"created_at": "2023-11-02T01:45:54Z",
|
||||
"repoId": 527419347,
|
||||
"pullRequestNo": 976
|
||||
}
|
||||
]
|
||||
}
|
||||
@ -48,4 +48,4 @@ AudioOutput の output record を start させた状態で音声変換を開始
|
||||
#### マイク入力の確認
|
||||
|
||||
マイク入力自体に問題がある可能性があります。録音ソフトなどを用いてマイク入力を確認してみてください。
|
||||
また、[こちらの録音サイト](https://w-okada.github.io/voice-changer/)は VCClient の姉妹品であり、ほぼ同等のマイク入力処理が行われているため参考になります。(インストール不要。ブラウザのみで動きます。)
|
||||
また、[こちらの録音サイト](https://w-okada.github.io/voice-changer/)は VC Client の姉妹品であり、ほぼ同等のマイク入力処理が行われているため参考になります。(インストール不要。ブラウザのみで動きます。)
|
||||
|
||||
53
tutorials/trouble_shoot_communication_ko.md
Normal file
53
tutorials/trouble_shoot_communication_ko.md
Normal file
@ -0,0 +1,53 @@
|
||||
## 문제 해결법 통신편
|
||||
|
||||
음성이 전혀 변환되지 않는 경우나 변환 후 음성이 이상하게 될 경우에는 음성 변환 과정에서 문제점을 찾아야 합니다.
|
||||
|
||||
이 문서에서는 어떤 부분에서 문제가 발생하는지 대략적으로 찾을 수 있는 방법에 대한 설명입니다.
|
||||
|
||||
## VC Client의 구성과 문제 구분
|
||||
|
||||
<img src="https://user-images.githubusercontent.com/48346627/235551041-6eed4035-5542-47d1-bbd3-31fa7842011b.png" width="720">
|
||||
|
||||
사용자(음성 입력) → GUI → 변환 전 음성(1) → 서버 → 변환 후의 음성(2) → GUI에 도착한 변환 후 음성(3) → 스피커(음성 출력)
|
||||
|
||||
VC Client는 이미지 자료처럼 GUI(클라이언트)가 마이크를 통해 음성을 받고, 서버에서 변환하는 구성을 하고 있습니다.
|
||||
|
||||
VC Client는 이미지 자료 음성이 세 곳에서 어떤 상태인지 확인할 수 있습니다.
|
||||
정상 상태로 음성이 녹음됐다면 이 과정까지는 처리가 잘 된 것이고, 이후부터 문제를 찾으면 됩니다(문제 구분이라고 합니다).
|
||||
|
||||
## 음성의 상태 확인 방법
|
||||
|
||||
### (1)(2)로 음성 상태 확인
|
||||
|
||||
<img src="https://github.com/w-okada/voice-changer/assets/48346627/f4845f1d-2e1a-49c1-a226-0e50be807f2d" width="720">
|
||||
|
||||
Analyzer의 Sampling을 시작한 상태에서 음성 변환을 시도해 보세요. 어느 정도 음성을 입력 후에 Samplling을 정지하면 in/out에 재생 버튼이 표시됩니다.
|
||||
|
||||
- in에는 'VC Client의 구성과 문제 구분'의 이미지 자료(1)(GUI→서버)의 음성이 녹음되어 있습니다. 마이크로 입력된 음성이 그대로 서버에 녹음될 테니 사용자의 음성이 녹음됐다면 정상입니다.
|
||||
- out에는 'VC Client의 구성과 문제 구분'의 이미지 자료(2)(서버에서 변환한 후의 음성)의 음성이 녹음되어 있습니다. AI를 통해 변환된 음성이 녹음되어 있을 겁니다.
|
||||
|
||||
### (3)으로 음성 상태 확인
|
||||
|
||||
<img src="https://github.com/w-okada/voice-changer/assets/48346627/18ddfc2c-beb2-4e7a-8a06-1e00cc6ddb72" width="720">
|
||||
|
||||
Audio Output의 output record를 시작한 상태로 음성 변환을 시도해 보세요. 어느 정도 음성을 입력한 후에 정리하면 .wav 파일이 다운로드됩니다. 이 .wav 파일은 서버에서 전송된 변환 후의 음성이 녹음되어있을 겁니다.
|
||||
|
||||
## 음성 상태 확인 후
|
||||
|
||||
앞서 설명한 이미지 자료의 (1)~(3) 중에서 예상한 상태의 녹음 음성이 어디까지 진행됐나 파악했다면, 예상한 상태의 음성이 녹음된 곳 이후에도 문제가 없는지 검토하세요.
|
||||
|
||||
### (1)에서의 음성 상태가 이상한 경우
|
||||
|
||||
#### 음성 파일로 확인
|
||||
|
||||
음성 파일로 변환이 되는지 확인하세요.
|
||||
|
||||
예를 들어, 다음 파일을 사용해 보세요.
|
||||
|
||||
- [sample_jvs001](https://drive.google.com/file/d/142aj-qFJOhoteWKqgRzvNoq02JbZIsaG/view) from [JVS](https://sites.google.com/site/shinnosuketakamichi/research-topics/jvs_corpus)
|
||||
- [sample_jvs001](https://drive.google.com/file/d/1iCErRzCt5-6ftALcic9w5zXWrzVXryIA/view) from [JVS-MuSiC](https://sites.google.com/site/shinnosuketakamichi/research-topics/jvs_music)
|
||||
|
||||
#### 마이크 입력 확인
|
||||
|
||||
마이크 입력 자체에 문제가 있을 가능성이 있습니다. 녹음 프로그램 등을 사용해 마이크 입력을 확인하세요.
|
||||
또한 [이 녹음 사이트](https://w-okada.github.io/voice-changer/)는 VC Client의 자매품으로 마이크 입력 처리가 거의 동일하게 이루어져 참고할 만합니다. (설치 필요 없음. 브라우저에서만 동작합니다.)
|
||||
39
tutorials/tutorial_device_mode_ko.md
Normal file
39
tutorials/tutorial_device_mode_ko.md
Normal file
@ -0,0 +1,39 @@
|
||||
## Device Mode 튜토리얼
|
||||
|
||||
Device Mode에 대한 설명입니다.
|
||||
|
||||
[설명 영상](https://youtu.be/SUnRGCJ92K8?t=99)
|
||||
|
||||
## v.1.5.2.9 이전의 구성(client device mode)
|
||||
|
||||
v.1.5.2.9 이전에는 브라우저가 제어하는 마이크와 스피커를 사용해 음성 변환을 진행했습니다.
|
||||
이것을 client device mode라 부릅니다(빨간 화살표).
|
||||
|
||||

|
||||
|
||||
## v.1.5.2.9 이후의 구성(client device mode / server device mode)
|
||||
|
||||
v.1.5.2.9부터 PC에 접속된 마이크와 스피커를 직접 VC Client에서 제어해 음성 변환을 진행하는 모드를 추가했습니다. 이것을 server device mode라 부릅니다(파란 화살표)。
|
||||
|
||||

|
||||
|
||||
## client device mode / server device mode의 장점과 단점
|
||||
|
||||
v.1.5.2.9 이후에는 client device mode와 server device mode 중에서 사용할 것을 선택할 수 있게 됐습니다.
|
||||
|
||||
- client device mode
|
||||
- 장점
|
||||
1. Chrome이 마이크/스피커의 어려운 처리를 대신해 준다.
|
||||
2. 잡음 제거 등의 Chrome이 가진 Web 회의 기능을 사용할 수 있다.
|
||||
- 단점
|
||||
1. 다소 지연이 발생할 수 있다.
|
||||
- server device mode
|
||||
- 장점
|
||||
1. VC Client가 직접 마이크/스피커를 다뤄서 지연이 적다.
|
||||
- 단점
|
||||
1. 다룰 수 없는 마이크/스피커가 있을 수 있다.
|
||||
2. 잡음 제거 등 Chrome의 편리한 기능을 사용할 수 없다.
|
||||
|
||||

|
||||
|
||||
사용자는 각 장점·단점을 고려해 구분하여 사용할 수 있습니다.
|
||||
@ -10,7 +10,7 @@ v.1.5.3.7 から追加された server device mode における monitor output
|
||||
|
||||
## v.1.5.3.7 以降の構成
|
||||
|
||||
v.1.5.3.7 では、VCClient の server device mode でもう一つ出力先デバイスを設定できるようになりました(赤線)。これにより、モニター用には Voicemeeter を経由せずに直接 wasapi デバイスや asio デバイスに出力できるようになり、遅延が少ないモニタリングが可能になります。
|
||||
v.1.5.3.7 では、VC Client の server device mode でもう一つ出力先デバイスを設定できるようになりました(赤線)。これにより、モニター用には Voicemeeter を経由せずに直接 wasapi デバイスや asio デバイスに出力できるようになり、遅延が少ないモニタリングが可能になります。
|
||||
|
||||

|
||||
|
||||
|
||||
48
tutorials/tutorial_monitor_consept_ko.md
Normal file
48
tutorials/tutorial_monitor_consept_ko.md
Normal file
@ -0,0 +1,48 @@
|
||||
## 모니터링 튜토리얼
|
||||
|
||||
v.1.5.3.7부터 추가된 server device mode의 monitor output에 대한 설명입니다.
|
||||
|
||||
## v.1.5.3.6 이전의 구성
|
||||
|
||||
출력 대상 장치를 하나만 설정할 수 있었습니다. Discord나 Zoom 등 다른 애플리케이션에서 사용하기 위해서는 일반적으로 출력을 Voicemeeter와 같은 가상 오디오 장치 설정을 해야 할 필요가 있었습니다. 그로 인해 변환 후 음성을 확인하려면 가상 오디오 장치를 통해 확인해야 하는 등의 많은 수고가 필요했습니다(파란 화살표).
|
||||
|
||||

|
||||
|
||||
## v.1.5.3.7 이후의 구성
|
||||
|
||||
v.1.5.3.7에서는 VC Client의 server device mode에서 출력 대상 장치를 하나 더 설정할 수 있게 됐습니다(빨간 화살표). 이를 통해 모니터링용으로 Voicemeeter를 거치지 않고 직접 wasapi 장치나 asio 장치로 출력할 수 있게 되어 지연이 적은 모니터링이 가능해졌습니다.
|
||||
|
||||

|
||||
|
||||
## 사용 방법
|
||||
|
||||
장치 설정 구역에서 server device mode를 선택하세요. 샘플링 레이트(S.R.), input, output, monitor를 설정할 수 있게 됩니다.
|
||||
|
||||

|
||||
|
||||
## 주의 사항
|
||||
|
||||
server device mode에서 사용하는 input, output, monitor 각 장치의 샘플링 레이트는 일치해야 합니다. 일치하지 않을 경우에는 콘솔에 자세한 정보가 표시되므로 GUI에서 각 장치가 지원하는 샘플링 레이트를 지정하세요.
|
||||
|
||||
### 예시
|
||||
|
||||

|
||||
|
||||
샘플링 레이트가 일치하지 않으면 위와 같이 표시됩니다.
|
||||
|
||||
(1)는 현재 GUI에서 장치에 지정된 샘플링 레이트 지원 여부를 표시합니다. False인 장치는 지원하지 않습니다.
|
||||
|
||||
(2)에서 각 장치에서 지원하는 샘플링 레이트를 표시합니다. input, output, monitor 전부 지원하는 샘플링 레이트를 지정하세요. 예시에서는 48000으로 지정했습니다.
|
||||
|
||||
## 팁
|
||||
|
||||
### 첫 번째
|
||||
|
||||
사용 환경에 따라 크게 달라지겠지만, 개발자 환경에서는 input, monitor를 wasapi 장치로 output을 임의로 설정해 상당히 낮은 지연으로 사용할 수 있었습니다.
|
||||
(RTX 4090 사용)
|
||||
|
||||
### 두 번째
|
||||
|
||||
Wasapi의 샘플링 레이트는 장치에서 설정한 것만 선택할 수 있습니다. 이 설정은 Windows 사운드 설정에서 변경할 수 있습니다.(Win11)
|
||||
|
||||

|
||||
@ -233,7 +233,7 @@ If you have 2 or more GPUs, you can choose your GPU here.
|
||||
|
||||
Choose between client device mode and server device mode. You can only change it when the voice conversion is stopped.
|
||||
|
||||
For more details on each mode, please see [here](./tutorial_device_mode.md).
|
||||
For more details on each mode, please see [here](./tutorial_device_mode_ja.md).
|
||||
|
||||
### Audio Input
|
||||
|
||||
|
||||
@ -226,7 +226,7 @@ If you have 2 or more GPUs, you can choose your GPU here.
|
||||
|
||||
Choose between client device mode and server device mode. You can only change it when the voice conversion is stopped.
|
||||
|
||||
For more details on each mode, please see [here](./tutorial_device_mode.md).
|
||||
For more details on each mode, please see [here](./tutorial_device_mode_ja.md).
|
||||
|
||||
### Audio Input
|
||||
|
||||
|
||||
@ -238,10 +238,10 @@ In the onnxdirectML version, you can switch the GPU ON/OFF.
|
||||
|
||||
#### AUDIO
|
||||
|
||||
Choose the type of audio device you want to use. For more information, please refer to the [document](./tutorial_device_mode.md).
|
||||
Choose the type of audio device you want to use. For more information, please refer to the [document](./tutorial_device_mode_ja.md).
|
||||
|
||||
- Client: You can make use of the microphone input and speaker output with the GUI functions such as noise cancellation.
|
||||
- Server: VCClient can directly control the microphone and speaker to minimize latency.
|
||||
- Server: VC Client can directly control the microphone and speaker to minimize latency.
|
||||
|
||||
#### input
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
# Realtime Voice Changer Client for RVC Tutorial (v.1.5.3.13)
|
||||
|
||||
[Japanese/日本語](/tutorials/tutorial_rvc_ja_latest.md)
|
||||
[Japanese/日本語](/tutorials/tutorial_rvc_ja_latest.md) [Korean/한국어](/tutorials/tutorial_rvc_ko_latest.md)
|
||||
|
||||
# Introduction
|
||||
|
||||
@ -125,7 +125,7 @@ Icons are links.
|
||||
| <img src="https://github.com/w-okada/rvc-trainer-docker/assets/48346627/7bc188db-3aae-43eb-98a1-34aacc16173d" width="32"> spanner | tools |
|
||||
| <img src="https://github.com/w-okada/rvc-trainer-docker/assets/48346627/5db16acc-e901-40d2-8fc2-1fb9fd67f59c" width="32"> coffee | donation |
|
||||
|
||||
### claer setting
|
||||
### clear setting
|
||||
|
||||
Initialize configuration.
|
||||
|
||||
@ -267,10 +267,10 @@ Even if a GPU is not detected, gpu0 - gpu3 will still be displayed. If you speci
|
||||
|
||||
#### AUDIO
|
||||
|
||||
Choose the type of audio device you want to use. For more information, please refer to the [document](./tutorial_device_mode.md).
|
||||
Choose the type of audio device you want to use. For more information, please refer to the [document](./tutorial_device_mode_ja.md).
|
||||
|
||||
- Client: You can make use of the microphone input and speaker output with the GUI functions such as noise cancellation.
|
||||
- Server: VCClient can directly control the microphone and speaker to minimize latency.
|
||||
- Server: VC Client can directly control the microphone and speaker to minimize latency.
|
||||
|
||||
#### input
|
||||
|
||||
|
||||
@ -251,7 +251,7 @@ GPU を 2 枚以上持っている場合、ここで GPU を選べます。
|
||||
|
||||
client device mode と server device mode のどちらを使用するか選択します。音声変換が停止している時のみ変更できます。
|
||||
|
||||
それぞれのモードの詳細は[こちら](./tutorial_device_mode.md)をご覧ください。
|
||||
それぞれのモードの詳細は[こちら](./tutorial_device_mode_ja.md)をご覧ください。
|
||||
|
||||
### AudioInput
|
||||
|
||||
|
||||
@ -244,7 +244,7 @@ GPU を 2 枚以上持っている場合、ここで GPU を選べます。
|
||||
|
||||
client device mode と server device mode のどちらを使用するか選択します。音声変換が停止している時のみ変更できます。
|
||||
|
||||
それぞれのモードの詳細は[こちら](./tutorial_device_mode.md)をご覧ください。
|
||||
それぞれのモードの詳細は[こちら](./tutorial_device_mode_ja.md)をご覧ください。
|
||||
|
||||
### AudioInput
|
||||
|
||||
|
||||
@ -244,10 +244,10 @@ onnxdirectML 版では GPU の ON/OFF を切り替えることができます。
|
||||
|
||||
#### AUDIO
|
||||
|
||||
使用するオーディオデバイスのタイプを選びます。詳細は[こちらの文書](./tutorial_device_mode.md)をご確認ください。
|
||||
使用するオーディオデバイスのタイプを選びます。詳細は[こちらの文書](./tutorial_device_mode_ja.md)をご確認ください。
|
||||
|
||||
- client: ノイズ抑制機能など GUI(chrome)の機能を活用してマイク入力、スピーカー出力を行うことができます。
|
||||
- server: VCClient が直接マイクとスピーカーを操作します。遅延を抑えることができます。
|
||||
- server: VC Client が直接マイクとスピーカーを操作します。遅延を抑えることができます。
|
||||
|
||||
#### input
|
||||
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
# Realtime Voice Changer Client for RVC チュートリアル(v.1.5.3.13)
|
||||
|
||||
[English](/tutorials/tutorial_rvc_en_latest.md)
|
||||
[English](/tutorials/tutorial_rvc_en_latest.md) [Korean/한국어](/tutorials/tutorial_rvc_ko_latest.md)
|
||||
|
||||
# はじめに
|
||||
|
||||
@ -126,7 +126,7 @@ A7. フォルダのパスに unicode が含まれるとエラーが出るよう
|
||||
| <img src="https://github.com/w-okada/rvc-trainer-docker/assets/48346627/7bc188db-3aae-43eb-98a1-34aacc16173d" width="32"> スパナ | 各種便利ツールへのリンク |
|
||||
| <img src="https://github.com/w-okada/rvc-trainer-docker/assets/48346627/5db16acc-e901-40d2-8fc2-1fb9fd67f59c" width="32"> コーヒー | 開発者へ**寄付**するためのリンク |
|
||||
|
||||
### claer setting
|
||||
### clear setting
|
||||
|
||||
設定を初期化します。
|
||||
|
||||
@ -271,10 +271,10 @@ gpu0 - gpu3 は GPU が検出されなくても表示されます。存在しな
|
||||
|
||||
#### AUDIO
|
||||
|
||||
使用するオーディオデバイスのタイプを選びます。詳細は[こちらの文書](./tutorial_device_mode.md)をご確認ください。
|
||||
使用するオーディオデバイスのタイプを選びます。詳細は[こちらの文書](./tutorial_device_mode_ja.md)をご確認ください。
|
||||
|
||||
- client: ノイズ抑制機能など GUI(chrome)の機能を活用してマイク入力、スピーカー出力を行うことができます。
|
||||
- server: VCClient が直接マイクとスピーカーを操作します。遅延を抑えることができます。
|
||||
- server: VC Client が直接マイクとスピーカーを操作します。遅延を抑えることができます。
|
||||
|
||||
#### input
|
||||
|
||||
|
||||
373
tutorials/tutorial_rvc_ko_latest.md
Normal file
373
tutorials/tutorial_rvc_ko_latest.md
Normal file
@ -0,0 +1,373 @@
|
||||
# Realtime Voice Changer Client for RVC 튜토리얼(v.1.5.3.13)
|
||||
|
||||
[Japanese/日本語](/tutorials/tutorial_rvc_ja_latest.md) [English](/tutorials/tutorial_rvc_en_latest.md)
|
||||
|
||||
# 소개
|
||||
|
||||
이 애플리케이션은 여러 음성 변환 AI(VC, Voice Conversion)를 활용해 실시간 음성 변환을 위한 클라이언트 소프트웨어입니다. RVC, MMVCv13, MMVCv15, So-vits-svcv40 등의 모델을 지원하지만, 해당 문서에서는 [RVC(Retrieval-based-Voice-Conversion)](https://github.com/liujing04/Retrieval-based-Voice-Conversion-WebUI)를 중심으로 음성 변환 튜토리얼에 대해 진행합니다. 기본적인 방법은 크게 다르지 않습니다.
|
||||
|
||||
아래에는 원본 [Retrieval-based-Voice-Conversion-WebUI](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI)를 원본 RVC로 표기하고, ddPn08 님이 작성한 [RVC-WebUI](https://github.com/ddPn08/rvc-webui)를 ddPn08RV로 표기합니다.
|
||||
|
||||
## 주의 사항
|
||||
|
||||
- 모델 학습은 별도로 진행해야 합니다.
|
||||
- 개인적으로 학습을 진행할 경우에는 [원본 RVC](https://github.com/liujing04/Retrieval-based-Voice-Conversion-WebUI) 또는 [ddPn08RVC](https://github.com/ddPn08/rvc-webui)로 진행하세요.
|
||||
- 브라우저에서 학습용 음성을 사용할 때는 [녹음 앱 on Github Pages](https://w-okada.github.io/voice-changer/)를 사용하는 것이 편리합니다.
|
||||
- [설명 영상](https://youtu.be/s_GirFEGvaA)
|
||||
- [학습 팁](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/jp/training_tips_ja.md)가 공개되어 있으니 참조해 주세요.
|
||||
|
||||
# 시작하기까지
|
||||
|
||||
## GUI 실행
|
||||
|
||||
### Windows 버전
|
||||
|
||||
다운로드 받은 zip 파일의 압축을 풀고 `start_http.bat`을 실행하세요.
|
||||
|
||||
이미 구버전을 갖고 있다면 반드시 서로 다른 폴더에 압축을 푸세요.
|
||||
|
||||
### Mac 버전
|
||||
|
||||
다음과 같이 실행하세요.
|
||||
|
||||
1. 다운로드한 파일의 압축을 풉니다.
|
||||
|
||||
1. 다음으로 control 키를 누른 상태로 MMVCServerSIO를 클릭해 실행하세요(or 오른쪽 클릭으로 실행하세요). 확인되지 않은 개발자 메시지가 나오면 다시 control 키를 누르고 클릭해 실행하세요(or 오른쪽 클릭으로 실행하세요). 터미널이 열리고 몇 초가 지나면 처리가 완료됩니다.
|
||||
|
||||
1. 다음으로 control 키를 누른 상태로 startHTTP.command를 클릭해 실행하세요(or 오른쪽 클릭으로 실행하세요). 확인되지 않은 개발자 메시지가 나오면 다시 control 키를 누르고 클릭해 실행하세요(or 오른쪽 클릭으로 실행하세요). 터미널이 열리고 몇 초가 지나면 처리가 완료됩니다.
|
||||
|
||||
※ 다시 말해, MMVCServerSIO와 startHTTP.command 둘 다 실행하는 것이 포인트입니다. 그리고 MMVCServerSIO 를 먼저 실행해야 합니다.
|
||||
|
||||
이미 구버전을 갖고 있다면 반드시 서로 다른 폴더에 압축을 푸세요.
|
||||
|
||||
### 원격 연결 시 주의 사항
|
||||
|
||||
원격으로 접속할 때는 http 대신 https `.bat` 파일(win)、`.command` 파일(mac)을 실행하세요.
|
||||
|
||||
브라우저(Chrome에서만 지원)에서 접속하면 화면이 나옵니다.
|
||||
|
||||
### 컨트롤 표시
|
||||
|
||||
`.bat` 파일(win) 혹은 `.command` 파일(mac)을 실행하면 다음과 같은 화면이 나오며 처음 실행할 때는 인터넷으로 여러 데이터를 다운로드합니다.
|
||||
사용 환경에 따라 다르지만, 보통 1~2분 정도 소요됩니다.
|
||||
|
||||

|
||||
|
||||
### GUI 설명
|
||||
|
||||
실행에 필요한 데이터 다운로드가 완료되면 다음과 같은 메시지 창이 나옵니다. 괜찮으시다면 노란 아이콘을 클릭해 개발자에게 따뜻한 커피 한잔 부탁드립니다. 시작 버튼을 누르면 메시지 창이 사라집니다.
|
||||
|
||||

|
||||
|
||||
# GUI
|
||||
|
||||
다음과 같은 화면이 나오면 성공입니다.
|
||||
|
||||

|
||||
|
||||
# 빠른 시작
|
||||
|
||||
## 조작 방법
|
||||
|
||||
실행할 때 다운로드한 데이터를 사용해 즉시 음성 변환을 할 수 있습니다.
|
||||
|
||||
(1) 모델 선택 구역에서 사용하고 싶은 모델을 클릭하세요. 모델이 사용 준비가 되면 모델에 설정된 캐릭터 이미지가 표시됩니다.
|
||||
|
||||
(2) 사용할 마이크(input)와 스피커(output)를 선택하세요. 설정이 어려우시다면 클라이언트를 선택하고 마이크와 스피커를 선택하는 것을 추천합니다. (서버와의 차이는 아래에서 설명합니다.)
|
||||
|
||||
(3) 시작 버튼을 누르면 몇 초간의 데이터 준비 후에 음성 변환이 시작됩니다. 마이크에 말을 해보세요. 스피커에서 변환된 음성이 들릴 겁니다.
|
||||
|
||||

|
||||
|
||||
## 빠른 시작에 관한 FAQ
|
||||
|
||||
Q1. 소리가 띄엄띄엄 들립니다.
|
||||
|
||||
A1. PC 성능이 충분하지 않을 가능성이 있습니다. CHUNK 값을 높여보세요(아래 사진(A)). (1024 등). 또한 F0 Det를 dio로 바꿔보세요(아래 사진(B)).
|
||||
|
||||

|
||||
|
||||
Q2. 음성이 바뀌지 않습니다.
|
||||
|
||||
A2. [이곳](https://github.com/w-okada/voice-changer/blob/master/tutorials/trouble_shoot_communication_ko.md)을 참조해 문제가 있는 곳을 파악하고 해결해 보세요.
|
||||
|
||||
Q3. 음정이 이상합니다.
|
||||
|
||||
A3. 빠른 시작에서는 설명하지 않았는데 Pitch 조정이 가능한 모델은 TUNE에서 변경할 수 있습니다. 아래에 작성된 상세 설명을 확인하세요.
|
||||
|
||||
Q4. 윈도우 창이 나오지 않습니다. 또는 창은 나오지만 내용이 나오지 않습니다. 콘솔에 `electron: Failed to load URL: http://localhost:18888/ with error: ERR_CONNECTION_REFUSED` 같은 오류가 나옵니다.
|
||||
|
||||
A4. 바이러스 검사가 진행 중일 가능성이 있습니다. 잠시 기다리거나 폴더를 검사 제외 지정하세요(이에 개발자는 책임이 없습니다).
|
||||
|
||||
Q5. `[4716:0429/213736.103:ERROR:gpu_init.cc(523)] Passthrough is not supported, GL is disabled, ANGLE is`라는 메시지 창이 나옵니다.
|
||||
|
||||
A5. 사용 중인 라이브러리가 내보내는 오류입니다. 큰 문제가 있는 것은 아니니 무시하고 사용하셔도 됩니다.
|
||||
|
||||
Q6. (AMD 사용자) GPU를 사용하지 않는 것 같습니다.
|
||||
|
||||
A6. DirectML 버전을 사용하세요. 또한, AMD GPU는 ONNX 모델에서만 사용할 수 있습니다. 성능 모니터에서 GPU 사용률이 높아지는 것을 통해 확인할 수 있습니다. ([see here](https://github.com/w-okada/voice-changer/issues/383))
|
||||
|
||||
Q7. onxxruntime 가 오류를 출력하고 실행되지 않습니다.
|
||||
|
||||
A7. 폴더 경로에 한글(유니코드)이 포함되면 오류가 나오는 것 같습니다. 유니코드가 없는 경로(영문, 숫자만)에 압축을 해제하세요. (참고: https://github.com/w-okada/voice-changer/issues/528)
|
||||
|
||||
# GUI 상세 설명
|
||||
|
||||
## 타이틀
|
||||
|
||||

|
||||
|
||||
타이틀 아래의 아이콘은 링크입니다.
|
||||
|
||||
| 아이콘 | 링크 |
|
||||
| :------------------------------------------------------------------------------------------------------------------------------------ | :-------------------------- |
|
||||
| <img src="https://github.com/w-okada/rvc-trainer-docker/assets/48346627/97c18ca5-eee5-4be2-92a7-8092fff960f2" width="32"> Octocat | github 저장소 링크 |
|
||||
| <img src="https://github.com/w-okada/rvc-trainer-docker/assets/48346627/751164e4-7b7d-4d7e-b49c-1ad660bf7439" width="32"> 물음표 표시 | 매뉴얼 링크 |
|
||||
| <img src="https://github.com/w-okada/rvc-trainer-docker/assets/48346627/7bc188db-3aae-43eb-98a1-34aacc16173d" width="32"> 스패너 | 여러 편리한 도구 링크 |
|
||||
| <img src="https://github.com/w-okada/rvc-trainer-docker/assets/48346627/5db16acc-e901-40d2-8fc2-1fb9fd67f59c" width="32"> 커피 | 개발자를 위한 **기부** 링크 |
|
||||
|
||||
### 설정 초기화
|
||||
|
||||
설정을 초기화합니다.
|
||||
|
||||
## 모델 선택 구역
|
||||
|
||||

|
||||
|
||||
사용할 모델을 선택할 수 있습니다.
|
||||
|
||||
편집 버튼을 누르면 모델 리스트(모델 슬롯)를 편집할 수 있습니다. 자세한 설명은 모델 슬롯 편집 화면을 확인하세요.
|
||||
|
||||
## 메인 컨트롤 구역
|
||||
|
||||
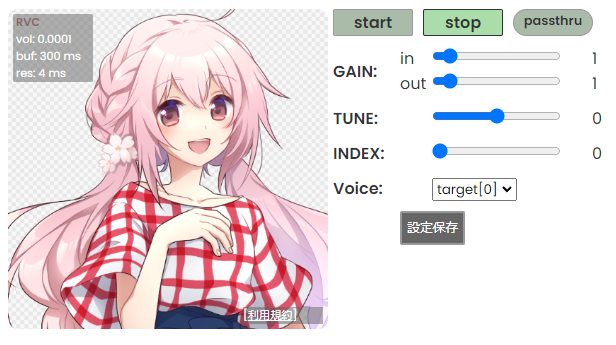
|
||||
|
||||
준비된 모델 캐릭터 사진이 좌측에 표시됩니다. 캐릭터 사진의 좌측 상단에 실시간 변환 상황이 오버레이로 표시됩니다.
|
||||
|
||||
우측의 버튼과 슬라이더로 여러 값을 조정할 수 있습니다.
|
||||
|
||||
### 실시간 변환 상황
|
||||
|
||||
수음부터 변환까지의 지연 시간은 `buf + res초`입니다. 조정할 때는 buf가 res보다 크도록 조정하세요
|
||||
|
||||
또한, 기기를 server device 모드로 사용할 때는 buf가 표시되지 않습니다. CHUNK에 표시된 값을 참조해 조정해 주세요.
|
||||
|
||||
#### vol
|
||||
|
||||
음성 변환 후의 음량입니다.
|
||||
|
||||
#### buf
|
||||
|
||||
음성을 잘라내는 한 구간의 길이(ms)입니다. CHUNK를 줄이면 이 값이 줄어듭니다.
|
||||
|
||||
#### res
|
||||
|
||||
CHUNK와 EXTRA를 합한 데이터를 변환하는 데 걸리는 시간입니다. CHUNK와 EXTRA 중 어느 쪽이든 줄이면 값이 줄어듭니다.
|
||||
|
||||
### 컨트롤
|
||||
|
||||
#### 시작/정지 버튼
|
||||
|
||||
시작 버튼으로 음성 변환을 시작, 정지 버튼으로 음성 변환을 정지합니다.
|
||||
|
||||
#### pass through 버튼
|
||||
|
||||
음성을 변환하지 않고 원래 상태 그대로 출력합니다. 기본적으로 적용할 때 확인 메시지 창이 나오지만, 고급 설정에서 확인 메시지 창을 무시하도록 설정할 수 있습니다.
|
||||
|
||||
#### GAIN
|
||||
|
||||
- in: 모델에 입력되는 음성의 음량을 조절할 수 있습니다.
|
||||
|
||||
- out: 변환 후의 음성의 음량을 조절할 수 있습니다.
|
||||
|
||||
#### TUNE
|
||||
|
||||
목소리의 Pitch를 얼마나 변환할지에 대한 값입니다. 추론 중에 변환할 수도 있습니다. 다음은 설정 기준입니다.
|
||||
|
||||
- 남자 목소리 → 여자 목소리로 변환할 경우 +12
|
||||
- 여자 목소리 → 남자 목소리로 변환할 경우 -12
|
||||
|
||||
#### INDEX (RVC만 해당)
|
||||
|
||||
학습에서 사용한 특징에 대한 비율을 지정합니다. index 파일이 등록된 모델에서만 적용됩니다.
|
||||
0이면 HuBERT의 출력을 그대로 사용하고, 1이면 모든 특징량을 사용합니다.
|
||||
index ratio가 0보다 크면 검색 시간이 오래 걸릴 수 있습니다.
|
||||
|
||||
#### Voice
|
||||
|
||||
음성 변환 대상을 설정합니다
|
||||
|
||||
#### 설정 저장 버튼
|
||||
|
||||
설정한 내용을 저장합니다. 모델을 다시 불러올 때 설정 내용이 반영됩니다. (일부 제외)
|
||||
|
||||
#### ONNX 출력 (RVC만 해당)
|
||||
|
||||
PyTorch의 모델을 ONNX로 변환해 출력합니다. 준비된 모델이 RVC PyTorch 모델일 때만 적용됩니다.
|
||||
|
||||
#### 그 외
|
||||
|
||||
사용하는 음성 변환 AI 모델에 따라 설정 가능한 내용이 달라집니다. 모델 개발 사이트에서 기능 등을 확인하세요.
|
||||
|
||||
## 상세 설정 구역
|
||||
|
||||

|
||||
|
||||
동작 설정이나 변환 처리 내용을 확인할 수 있습니다.
|
||||
|
||||
#### NOISE
|
||||
|
||||
잡음 제거 기능의 ON/OFF를 할 수 있습니다. Client Device 모드에서만 적용됩니다.
|
||||
|
||||
- Echo: 에코 캔슬 기능
|
||||
- Sup1, Sup2: 잡음 억제 기능
|
||||
|
||||
#### F0 Det (F0 Extractor)
|
||||
|
||||
Pitch 추출을 위한 알고리즘을 선택할 수 있습니다. 다음 중에서 선택할 수 있습니다. AMD GPU는 ONNX일 때만 적용됩니다.
|
||||
|
||||
| F0 Extractor | type | description |
|
||||
| ------------ | ----- | ------------------------------- |
|
||||
| dio | cpu | 경량 버전 |
|
||||
| harvest | cpu | 높은 정확도 |
|
||||
| crepe | torch | GPU를 사용함. 고속, 높은 정확도 |
|
||||
| crepe full | onnx | GPU를 사용함. 고속, 높은 정확도 |
|
||||
| crepe tiny | onnx | GPU를 사용함. 고속, 경량 버전 |
|
||||
| rnvpe | torch | GPU를 사용함. 고속, 높은 정확도 |
|
||||
|
||||
#### S. Thresh (Noise Gate)
|
||||
|
||||
음성 변환 음량의 임계치입니다. 이 값보다 작은 rms일 때는 음성 변환을 하지 않고 무음이 됩니다.
|
||||
(이 경우에는 변환 과정을 건너뛰기 때문에 부하가 많이 걸리지 않습니다.)
|
||||
|
||||
#### CHUNK (Input Chunk Num)
|
||||
|
||||
한 번에 얼마만큼의 길이를 잘라서 변환할 건지 정할 수 있습니다. 이 값이 클수록 효율적으로 변환하지만, buf 값이 커질수록 변환이 시작되기까지의 최대 시간이 길어집니다. buff:에 대략적인 시간이 표시됩니다.
|
||||
|
||||
#### EXTRA (Extra Data Length)
|
||||
|
||||
음성을 변환할 때, 과거의 음성을 얼마나 길게 입력할지 정할 수 있습니다. 과거의 음성이 길게 입력될수록 변환 정확도는 높아지지만 그만큼 계산 시간이 길어져서 res가 길어집니다.
|
||||
(아마도 Transformer가 문제라서 계산 시간이 길이의 제곱만큼 늘어날 것입니다)
|
||||
|
||||
자세한 내용은 [이 자료](https://github.com/w-okada/voice-changer/issues/154#issuecomment-1502534841)를 확인하세요.
|
||||
|
||||
#### GPU
|
||||
|
||||
onnxgpu 버전에서는 사용할 GPU를 선택할 수 있습니다.
|
||||
|
||||
onnxdirectML 버전에서는 GPU ON/OFF를 할 수 있습니다.
|
||||
|
||||
DirectML 버전일 때는 아래와 같은 버튼들이 나옵니다.
|
||||
|
||||

|
||||
|
||||
- cpu: cpu를 사용합니다.
|
||||
- gpu0: gpu0를 사용합니다.
|
||||
- gpu1: gpu1를 사용합니다.
|
||||
- gpu2: gpu2를 사용합니다.
|
||||
- gpu3: gpu3를 사용합니다.
|
||||
|
||||
gpu0 - gpu3은 GPU가 검출되지 않아도 표시됩니다. 존재하지 않는 GPU를 지정하면 CPU가 사용됩니다. [상세](https://github.com/w-okada/voice-changer/issues/410)
|
||||
|
||||
#### AUDIO
|
||||
|
||||
사용할 오디오 장치를 선택할 수 있습니다. 자세한 내용은 [이 문서](./tutorial_device_mode_ko.md)를 확인하세요.
|
||||
|
||||
- client: 소음 억제 기능 등 GUI(chrome)의 기능을 활용해 마이크 입력, 스피커 출력을 할 수 있습니다.
|
||||
- server: VC Client가 직접 마이크와 스피커를 조작합니다. 지연을 줄일 수 있습니다.
|
||||
|
||||
#### input
|
||||
|
||||
마이크 입력 등의 음성 입력 장치를 선택할 수 있습니다. 음성 파일에서의 입력도 가능합니다(파일 크기 제한 있음).
|
||||
|
||||
Windows 버전에서는 시스템 사운드를 입력으로 사용할 수 있습니다. 단, 시스템 사운드를 출력으로 사용하면 소리가 반복(하울링)되므로 주의하세요.
|
||||
|
||||
#### output
|
||||
|
||||
스피커 출력 등의 음성 출력 장치를 선택할 수 있습니다.
|
||||
|
||||
#### monitor
|
||||
|
||||
모니터링 스피커 출력 등의 음성 출력 장치를 선택할 수 있습니다. server device 모드일 때만 적용됩니다.
|
||||
|
||||
자세한 내용은 [이 문서](./tutorial_monitor_consept_ko.md)를 확인하세요.
|
||||
|
||||
#### REC.
|
||||
|
||||
변환 후의 음성을 파일로 저장할 수 있습니다.
|
||||
|
||||
### ServerIO Analizer
|
||||
|
||||
음성 변환 AI에 입력된 음성과 음성 변환 AI에서 출력된 음성을 녹음하고 확인할 수 있습니다.
|
||||
|
||||
대략적인 개념은 [이 문서](trouble_shoot_communication_ko.md)를 확인하세요.
|
||||
|
||||
#### SIO rec.
|
||||
|
||||
음성 변환 AI에 입력된 음성과 음성 변환 AI에서 출력된 음성 녹음을 시작/정지할 수 있습니다.
|
||||
|
||||
#### output
|
||||
|
||||
녹음된 음성을 재생할 스피커를 설정할 수 있습니다.
|
||||
|
||||
#### in
|
||||
|
||||
음성 변환 AI에 입력된 음성을 재생할 수 있습니다.
|
||||
|
||||
#### out
|
||||
|
||||
음성 변환 AI에서 출력된 음성을 재생할 수 있습니다.
|
||||
|
||||
### more...
|
||||
|
||||
더 높은 수준의 조작을 할 수 있습니다.
|
||||
|
||||
#### Merge Lab
|
||||
|
||||
모델 합성을 할 수 있습니다.
|
||||
|
||||
#### Advanced Setting
|
||||
|
||||
더 높은 수준의 설정을 할 수 있습니다.
|
||||
|
||||
#### Server Info
|
||||
|
||||
현재 서버의 설정을 확인할 수 있습니다.
|
||||
|
||||
# 모델 슬롯 편집 화면
|
||||
|
||||
모델 슬롯 선택 구역에서 편집 버튼을 누르면 모델 슬롯을 편집할 수 있습니다
|
||||
|
||||

|
||||
|
||||
## 아이콘 구역
|
||||
|
||||
아이콘을 클릭해 사진을 변경할 수 있습니다.
|
||||
|
||||
## 파일 구역
|
||||
|
||||
파일명을 클릭해 다운로드 할 수 있습니다.
|
||||
|
||||
## 업로드 버튼
|
||||
|
||||
모델을 업로드할 수 있습니다.
|
||||
|
||||
업로드 화면에서는 업르도할 보이스 체인저 유형을 선택할 수 있습니다.
|
||||
|
||||
돌아가기 버튼으로 모델 슬롯 편집 화면으로 돌아갈 수 있습니다.
|
||||
|
||||

|
||||
|
||||
## 샘플 버튼
|
||||
|
||||
샘플을 다운로드할 수 있습니다.
|
||||
|
||||
돌아가기 버튼을 눌러 모델 슬롯 편집 화면으로 돌아갈 수 있습니다.
|
||||
|
||||

|
||||
|
||||
## 편집 버튼
|
||||
|
||||
모델의 상세 정보를 편집할 수 있습니다.
|
||||
|
||||
편집할 수 있는 항목은 모델에 따라 다릅니다.
|
||||
Loading…
Reference in New Issue
Block a user