# Realtime Voice Changer Client for RVC チュートリアル(v.1.5.3.13)
[English](/tutorials/tutorial_rvc_en_latest.md) [Korean/한국어](/tutorials/tutorial_rvc_ko_latest.md)
# はじめに
本アプリケーションは、各種音声変換 AI(VC, Voice Conversion)を用いてリアルタイム音声変換を行うためのクライアントソフトウェアです。RVC, MMVCv13, MMVCv15, So-vits-svcv40 などのモデルに対応していますが本ドキュメントでは[RVC(Retrieval-based-Voice-Conversion)](https://github.com/liujing04/Retrieval-based-Voice-Conversion-WebUI)を題材に音声変換のためのチュートリアルを行います。基本的な操作は大きく変わりません。
以下、本家の[Retrieval-based-Voice-Conversion-WebUI](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI)を本家 RVC と表記し、ddPn08 氏の作成した[RVC-WebUI](https://github.com/ddPn08/rvc-webui)を ddPn08RVC と記載します。
## 注意事項
- 学習については別途行う必要があります。
- 自身で学習を行う場合は[本家 RVC](https://github.com/liujing04/Retrieval-based-Voice-Conversion-WebUI)または[ddPn08RVC](https://github.com/ddPn08/rvc-webui)で行ってください。
- ブラウザ上で学習用の音声を用意するには[録音アプリ on Github Pages](https://w-okada.github.io/voice-changer/)が便利です。
- [解説動画](https://youtu.be/s_GirFEGvaA)
- [training の TIPS](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/blob/main/docs/training_tips_ja.md)が公開されているので参照してください。
# 起動まで
## GUI の起動
### Windows 版、
ダウンロードした zip ファイルを解凍して、`start_http.bat`を実行してください。
旧バージョンをお持ちの方は、必ず別のフォルダに解凍するようにしてください。
### Mac 版
次のように起動します。
1. ダウンロードファイルを解凍します。
1. 次に、MMVCServerSIO をコントロールキーを押しながらクリックして実行します(or 右クリックから実行します)。開発元を検証できない旨が表示される場合は、再度コントロールキーを押しながらクリックして実行します(or 右クリックから実行します)。ターミナルが開き、数秒で処理が終了します。
1. 次に、startHTTP.command をコントロールキーを押しながらクリックして実行します(or 右クリックから実行します)。開発元を検証できない旨が表示される場合は、再度コントロールキーを押しながらクリックして実行します(or 右クリックから実行してください)。ターミナルが開き起動処理が開始します。
※ つまり、MMVCServerSIO と、startHTTP.command の両方で実行を行うのがポイントです。そして、MMVCServerSIO の方を先に実行しておく必要があります。
旧バージョンをお持ちの方は、必ず別のフォルダに解凍するようにしてください。
### リモート接続時の注意
リモートから接続する場合は、`.bat`ファイル(win)、`.command`ファイル(mac)の http が https に置き換わっているものを使用してください。
ブラウザ(Chrome のみサポート)でアクセスすると画面が表示されます。
### コンソール表示
`.bat`ファイル(win)や`.command`ファイル(mac)を実行すると、次のような画面が表示され、初回起動時には各種データをインターネットからダウンロードします。
お使いの環境によりますが、多くの場合1~2分かかります。

### GUI 表示
起動に必要なデータのダウンロードが完了すると下記のような ダイアログが表示されます。よろしければ黄色いアイコンを押して開発者にコーヒーをご馳走してあげてください。スタートボタンを押すとダイアログが消えます。

# GUI
下記のような画面が出れば成功です。

# クイックスタート
## 操作方法
起動時にダウンロードしたデータを用いて、すぐに音声変換を行うことができます。
(1) モデル選択エリアから使いたいモデルをクリックします。モデルがロードされるとモデルに設定されているキャラクタの画像が画面に表示されます。
(2) 使用するマイク(input)とスピーカー(output)を選択します。慣れていない方は、client を選択して、マイクとスピーカーを選択することを推奨します。(server との違いは後述します。)
(3) スタートボタンを押すと、数秒のデータロードの後に音声変換が開始されます。マイクに何かしゃべってみてください。スピーカーから変換後の音声が聞こえてくると思います。

## クイックスタートにおける FAQ
Q1. 音がとぎれとぎれになってしまう。
A1. PC の性能が十分ではない可能性があります。CHUNK の値を大きくしてみてください(下図(A))。(1024 など)。また F0 Det を dio にしてみてください(下図(B))。

Q2. 音声が変換されない。
A2. [こちら](https://github.com/w-okada/voice-changer/blob/master/tutorials/trouble_shoot_communication_ja.md)を参照して問題点の場所を明らかにして、対応を検討してください。
Q3. 音程がおかしい
A3. クイックスタートでは説明しませんでしたが、Pitch 変更可能なモデルであれば TUNE で変更できます。後述の詳細説明をご確認ください。
Q4. ウィンドウが表示されない。あるいはウィンドウは表示されるが中身が表示されない。コンソールに`electron: Failed to load URL: http://localhost:18888/ with error: ERR_CONNECTION_REFUSED`のようなエラーが表示される。
A4. ウィルスチェッカーが走っている可能性があります。しばらく待つか、自己責任でフォルダを除外指定してください。
Q5. `[4716:0429/213736.103:ERROR:gpu_init.cc(523)] Passthrough is not supported, GL is disabled, ANGLE is`という表示が出る
A5. 使用しているライブラリが出しているエラーです。影響はありませんので無視してください。
Q6. (AMD ユーザ) GPU が使用されていないような気がする。
A6. DirectML 版を使用してください。また、AMD の GPU は ONNX モデルでのみ有効になります。パフォーマンスモニターで GPU の使用率が上がっていることで判断できます。([see here](https://github.com/w-okada/voice-changer/issues/383))
Q7. onxxruntime がエラーを出力して起動しない。
A7. フォルダのパスに unicode が含まれるとエラーが出るようです。unicode を使わないパス(英数字のみ)に解凍してください。(参考:https://github.com/w-okada/voice-changer/issues/528)
# GUI の詳細
## タイトルエリア

タイトル下のアイコンはリンクになっています。
| アイコン | リンク |
| :------------------------------------------------------------------------------------------------------------------------------------------- | :------------------------------- |
|  Octocat | github のリポジトリへのリンク |
|
Octocat | github のリポジトリへのリンク |
|  クエスションマーク | マニュアル へのリンク |
|
クエスションマーク | マニュアル へのリンク |
|  スパナ | 各種便利ツールへのリンク |
|
スパナ | 各種便利ツールへのリンク |
|  コーヒー | 開発者へ**寄付**するためのリンク |
### clear setting
設定を初期化します。
## モデル選択エリア

使用するモデルを選択します。
編集ボタンを押すと、モデル一覧(モデルスロット)を編集することができます。詳細はモデルスロット編集画面をご確認ください。
## メインコントロールエリア
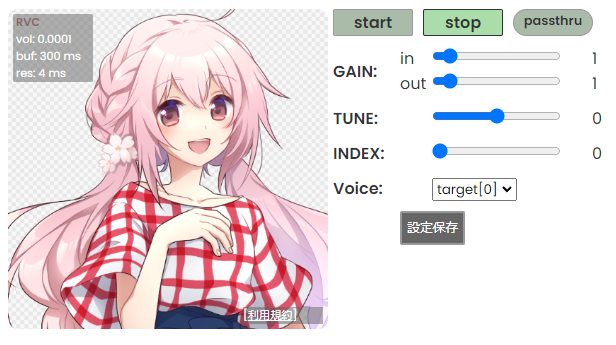
左側にロードされたモデルのキャラクタ画像が表示されます。キャラクタ画像の左上にリアルタイム変換の状況がオーバレイ表示されます。
右側のボタンやスライダーで各種コントロールを行います。
### リアルタイム変換の状況
声を出してから変換までのラグは`buf + res秒`です。調整の際は buf の時間が res よりも長くなるように調整してください。
なお、デバイスを server device モードで使用している場合は buf の表示は行われません。CHUNK に表示されている値を目安に調整してください。
#### vol
音声変換後の音量です。
#### buf
音声を切り取る一回の区間の長さ(ms)です。CHUNK を短くするとこの数値が減ります。
#### res
CHUNK と EXTRA を足したデータを変換にかかる時間です。CHUNK と EXTRA のいずれでも短くすると数値が減ります。
### コントロール
#### start/stop ボタン
start で音声変換を開始、stop で音声変換を停止します
#### pass through ボタン
音声を変換せずにそのまま出力します。デフォルトでは有効時に確認ダイアログが表示されますが、Advanced Setting で確認ダイアログをスキップする設定ができます。
#### GAIN
- in: モデルへの入力音声の音量の大きさを変化させます。
- out: 変換後の音声の音量の大きさを変化させます。
#### TUNE
声のピッチをどれくらい変換するかの値を入れます。推論中に変換もできます。以下は設定の目安です。
- 男声 → 女声 の変換では+12
- 女声 → 男声 の変換では-12
#### INDEX (RVC のみ)
学習で使用した特徴量に寄せる比率を指定します。index ファイルが登録されているモデルのみ有効です。
0 で HuBERT の出力をそのまま使う、1 で元の特徴量にすべて寄せます。
index ratio が 0 より大きいと検索に時間がかかる場合があります。
#### Voice
音声変換先の話者を設定します。
#### 設定保存ボタン
設定した内容を保存します。モデルを再度呼び出したときに設定内容が反映されます。(一部のぞく)
#### ONNX 出力 (RVC のみ)
PyTorch のモデルを ONNX に変換して出力します。ロードされているモデルが RVC の PyTorch モデルである場合のみ有効です。
#### その他
使用する音声変換 AI モデルにより設定可能な内容が増減します。モデル開発元のサイトなどで機能等をご確認ください。
## 詳細設定エリア

動作設定や変換処理の内容を確認することができます。
#### NOISE
ノイズ除去機能の ON/OFF を切り替えられます。Client Device モードでのみ有効です。
- Echo: エコーキャンセル機能
- Sup1, Sup2: ノイズ抑制機能です
#### F0 Det (F0 Extractor)
ピッチを抽出するためのアルゴリズムを選びます。次の中から選べます。AMD の GPU は onnx に対してのみ有効です。
| F0 Extractor | type | description |
| ------------ | ----- | -------------------------- |
| dio | cpu | 軽量 |
| harvest | cpu | 高精度 |
| crepe | torch | GPU を使用する高速、高精度 |
| crepe full | onnx | GPU を使用する高速、高精度 |
| crepe tiny | onnx | GPU を使用する高速、軽量版 |
| rnvpe | torch | GPU を使用する高速、高精度 |
#### S. Thresh (Noise Gate)
音声変換を行う音量の閾地です。この値より小さい rms の時は音声変換をせず無音を返します。
(この場合、変換処理がスキップされるので、あまり負荷がかかりません。)
#### CHUNK (Input Chunk Num)
一度の変換でどれくらいの長さを切り取って変換するかを決めます。これが大きいほど効率的に変換できますが、buf の値が大きくなり変換が開始されるまでの最大の時間が伸びます。 buff: におよその時間が表示されます。
#### EXTRA (Extra Data Length)
音声を変換する際、入力にどれくらいの長さの過去の音声を入れるかを決めます。過去の音声が長く入っているほど変換の精度はよくなりますが、その分計算に時間がかかるため res が長くなります。
(おそらく Transformer がネックなので、これの長さの 2 乗で計算時間は増えます)
詳細は[こちらの資料](https://github.com/w-okada/voice-changer/issues/154#issuecomment-1502534841)をご覧ください。
#### GPU
onnxgpu 版では使用する GPU を選択することができます。
onnxdirectML 版では GPU の ON/OFF を切り替えることができます。
DirectML Version の場合は次のようなボタンが表示されます。

- cpu: cpu を使用します。
- gpu0: gpu0 を使用します
- gpu1: gpu1 を使用します
- gpu2: gpu2 を使用します
- gpu3: gpu3 を使用します
gpu0 - gpu3 は GPU が検出されなくても表示されます。存在しない GPU を指定した場合は CPU が使用されます。[詳細](https://github.com/w-okada/voice-changer/issues/410)
#### AUDIO
使用するオーディオデバイスのタイプを選びます。詳細は[こちらの文書](./tutorial_device_mode_ja.md)をご確認ください。
- client: ノイズ抑制機能など GUI(chrome)の機能を活用してマイク入力、スピーカー出力を行うことができます。
- server: VC Client が直接マイクとスピーカーを操作します。遅延を抑えることができます。
#### input
マイク入力など音声入力デバイスを選択できます。音声ファイルからのインプットも可能です(サイズ上限あり)。
ウィンドウズ版では、システムサウンドをインプットとして使用することができます。ただし、システムサウンドをアウトプットとして使用すると、音がループするので注意してください。
#### output
スピーカー出力など音声出力デバイスを選択できます。
#### monitor
モニター用にスピーカー出力など音声出力デバイスを選択できます。server device モードの場合のみ有効です。
詳細は[こちらの文書](./tutorial_monitor_consept_ja.md)をご確認ください。
#### REC.
変換後の音声をファイル出力します。
### ServerIO Analizer
音声変換 AI に入力される音声と音声変換 AI から出力される音声を録音し、確認することができます。
大まかな考え方は[こちらの文書](trouble_shoot_communication_ja.md)を確認ください。
#### SIO rec.
音声変換 AI に入力される音声と音声変換 AI から出力される音声を録音を開始/停止します。
#### output
録音した音声を再生するスピーカーを設定します。
#### in
音声変換 AI に入力される音声を再生します。
#### out
音声変換 AI から出力された音声を再生します。
### more...
より高度な操作を行うことができます。
#### Merge Lab
モデルの合成を行うことができます。
#### Advanced Setting
より高度な設定を行うことができます。
#### Server Info
現在のサーバの設定を確認することができます。
# モデルスロット編集画面
モデルスロット選択アリアで編集ボタンを押すとモデルスロットを編集することができます。

## アイコンエリア
アイコンをクリックすることで画像を変更することができます。
## ファイルエリア
ファイル名をクリックすることでダウンロードすることができます。
## アップロードボタン
モデルをアップロードできます。
アップロード画面ではアップロードするボイスチェンジャタイプを選択することができます。
戻るボタンでモデルスロット編集画面に戻ることができます。

## サンプルボタン
サンプルをダウンロードすることができます。
戻るボタンでモデルスロット編集画面に戻ることができます。

## 編集ボタン
モデルの詳細を編集することができます。
編集できる項目はモデルに応じて変わります。
コーヒー | 開発者へ**寄付**するためのリンク |
### clear setting
設定を初期化します。
## モデル選択エリア

使用するモデルを選択します。
編集ボタンを押すと、モデル一覧(モデルスロット)を編集することができます。詳細はモデルスロット編集画面をご確認ください。
## メインコントロールエリア

左側にロードされたモデルのキャラクタ画像が表示されます。キャラクタ画像の左上にリアルタイム変換の状況がオーバレイ表示されます。
右側のボタンやスライダーで各種コントロールを行います。
### リアルタイム変換の状況
声を出してから変換までのラグは`buf + res秒`です。調整の際は buf の時間が res よりも長くなるように調整してください。
なお、デバイスを server device モードで使用している場合は buf の表示は行われません。CHUNK に表示されている値を目安に調整してください。
#### vol
音声変換後の音量です。
#### buf
音声を切り取る一回の区間の長さ(ms)です。CHUNK を短くするとこの数値が減ります。
#### res
CHUNK と EXTRA を足したデータを変換にかかる時間です。CHUNK と EXTRA のいずれでも短くすると数値が減ります。
### コントロール
#### start/stop ボタン
start で音声変換を開始、stop で音声変換を停止します
#### pass through ボタン
音声を変換せずにそのまま出力します。デフォルトでは有効時に確認ダイアログが表示されますが、Advanced Setting で確認ダイアログをスキップする設定ができます。
#### GAIN
- in: モデルへの入力音声の音量の大きさを変化させます。
- out: 変換後の音声の音量の大きさを変化させます。
#### TUNE
声のピッチをどれくらい変換するかの値を入れます。推論中に変換もできます。以下は設定の目安です。
- 男声 → 女声 の変換では+12
- 女声 → 男声 の変換では-12
#### INDEX (RVC のみ)
学習で使用した特徴量に寄せる比率を指定します。index ファイルが登録されているモデルのみ有効です。
0 で HuBERT の出力をそのまま使う、1 で元の特徴量にすべて寄せます。
index ratio が 0 より大きいと検索に時間がかかる場合があります。
#### Voice
音声変換先の話者を設定します。
#### 設定保存ボタン
設定した内容を保存します。モデルを再度呼び出したときに設定内容が反映されます。(一部のぞく)
#### ONNX 出力 (RVC のみ)
PyTorch のモデルを ONNX に変換して出力します。ロードされているモデルが RVC の PyTorch モデルである場合のみ有効です。
#### その他
使用する音声変換 AI モデルにより設定可能な内容が増減します。モデル開発元のサイトなどで機能等をご確認ください。
## 詳細設定エリア

動作設定や変換処理の内容を確認することができます。
#### NOISE
ノイズ除去機能の ON/OFF を切り替えられます。Client Device モードでのみ有効です。
- Echo: エコーキャンセル機能
- Sup1, Sup2: ノイズ抑制機能です
#### F0 Det (F0 Extractor)
ピッチを抽出するためのアルゴリズムを選びます。次の中から選べます。AMD の GPU は onnx に対してのみ有効です。
| F0 Extractor | type | description |
| ------------ | ----- | -------------------------- |
| dio | cpu | 軽量 |
| harvest | cpu | 高精度 |
| crepe | torch | GPU を使用する高速、高精度 |
| crepe full | onnx | GPU を使用する高速、高精度 |
| crepe tiny | onnx | GPU を使用する高速、軽量版 |
| rnvpe | torch | GPU を使用する高速、高精度 |
#### S. Thresh (Noise Gate)
音声変換を行う音量の閾地です。この値より小さい rms の時は音声変換をせず無音を返します。
(この場合、変換処理がスキップされるので、あまり負荷がかかりません。)
#### CHUNK (Input Chunk Num)
一度の変換でどれくらいの長さを切り取って変換するかを決めます。これが大きいほど効率的に変換できますが、buf の値が大きくなり変換が開始されるまでの最大の時間が伸びます。 buff: におよその時間が表示されます。
#### EXTRA (Extra Data Length)
音声を変換する際、入力にどれくらいの長さの過去の音声を入れるかを決めます。過去の音声が長く入っているほど変換の精度はよくなりますが、その分計算に時間がかかるため res が長くなります。
(おそらく Transformer がネックなので、これの長さの 2 乗で計算時間は増えます)
詳細は[こちらの資料](https://github.com/w-okada/voice-changer/issues/154#issuecomment-1502534841)をご覧ください。
#### GPU
onnxgpu 版では使用する GPU を選択することができます。
onnxdirectML 版では GPU の ON/OFF を切り替えることができます。
DirectML Version の場合は次のようなボタンが表示されます。

- cpu: cpu を使用します。
- gpu0: gpu0 を使用します
- gpu1: gpu1 を使用します
- gpu2: gpu2 を使用します
- gpu3: gpu3 を使用します
gpu0 - gpu3 は GPU が検出されなくても表示されます。存在しない GPU を指定した場合は CPU が使用されます。[詳細](https://github.com/w-okada/voice-changer/issues/410)
#### AUDIO
使用するオーディオデバイスのタイプを選びます。詳細は[こちらの文書](./tutorial_device_mode_ja.md)をご確認ください。
- client: ノイズ抑制機能など GUI(chrome)の機能を活用してマイク入力、スピーカー出力を行うことができます。
- server: VC Client が直接マイクとスピーカーを操作します。遅延を抑えることができます。
#### input
マイク入力など音声入力デバイスを選択できます。音声ファイルからのインプットも可能です(サイズ上限あり)。
ウィンドウズ版では、システムサウンドをインプットとして使用することができます。ただし、システムサウンドをアウトプットとして使用すると、音がループするので注意してください。
#### output
スピーカー出力など音声出力デバイスを選択できます。
#### monitor
モニター用にスピーカー出力など音声出力デバイスを選択できます。server device モードの場合のみ有効です。
詳細は[こちらの文書](./tutorial_monitor_consept_ja.md)をご確認ください。
#### REC.
変換後の音声をファイル出力します。
### ServerIO Analizer
音声変換 AI に入力される音声と音声変換 AI から出力される音声を録音し、確認することができます。
大まかな考え方は[こちらの文書](trouble_shoot_communication_ja.md)を確認ください。
#### SIO rec.
音声変換 AI に入力される音声と音声変換 AI から出力される音声を録音を開始/停止します。
#### output
録音した音声を再生するスピーカーを設定します。
#### in
音声変換 AI に入力される音声を再生します。
#### out
音声変換 AI から出力された音声を再生します。
### more...
より高度な操作を行うことができます。
#### Merge Lab
モデルの合成を行うことができます。
#### Advanced Setting
より高度な設定を行うことができます。
#### Server Info
現在のサーバの設定を確認することができます。
# モデルスロット編集画面
モデルスロット選択アリアで編集ボタンを押すとモデルスロットを編集することができます。

## アイコンエリア
アイコンをクリックすることで画像を変更することができます。
## ファイルエリア
ファイル名をクリックすることでダウンロードすることができます。
## アップロードボタン
モデルをアップロードできます。
アップロード画面ではアップロードするボイスチェンジャタイプを選択することができます。
戻るボタンでモデルスロット編集画面に戻ることができます。

## サンプルボタン
サンプルをダウンロードすることができます。
戻るボタンでモデルスロット編集画面に戻ることができます。

## 編集ボタン
モデルの詳細を編集することができます。
編集できる項目はモデルに応じて変わります。